
はじめに
以前に作成した、netkeibaからWebスクレイピングで指定した期間の日本のレース結果を取得するプログラムを改修しました。
改修内容は、マルチプロセスでWebスクレイピングを実行、となります。
以前のプログラムはシングルプロセスで動作していました。そのため、1年分のレース結果の取得には約30時間ほど掛かっていました。
両親のデータを取得する処理を追加したことで、1ヶ月分のレース結果を取得するのに2~3時間ほど掛かるようになりました。
1年分のレース結果を取得するのに、約30時間ほど掛かりました。また、プログラム実行時のCPU使用率をタスクマネージャで確認したところ、CPU使用率は低く、使用しているコア数は1コアでした。端末の能力を充分に活用できていませんでした。
訓練データ(レース結果データ)の内容を試行錯誤しながら変えて、競馬予測モデルの精度向上を目指していたのですが、訓練データの作成に時間が掛かり、精度向上作業のやる気が低下していました。
もっと早く訓練データ(レース結果データ)を取得できないか。
今回の改修結果
・1年分のレース結果の取得に掛かる時間を約30時間から約6時間に短縮することができました。
・プログラムをマルチプロセスで動作するようにし、CPUを効率的に使用できるようになりました。
プログラムの概要
このプログラムで作成した関数を以下に示します。
multiprocessingモジュールを使用して並列処理を行い、複数のプロセスでレース結果を取得しています。また、Seleniumを使用してブラウザ自動化を行い、Webページからレース結果をスクレイピングしています。
各関数の組み合わせにより、プログラムは指定された期間のレース結果データを取得し、結合してCSVファイルに保存します。
| No. | 関数名 | 概要 |
| 1. | main() | プログラムの開始位置となります。 ・プールのサイズを設定します。 ・開始時間を記録します。 ・現在の日付を取得し、終了月と終了年を計算します。 ・処理する年のリストを作成します。 ・各年ごとに`get_race_info()`関数を並列実行します。 ・`combine_raceresult()`関数を使用してレース結果を結合し、CSVファイルに保存します。 ・実行時間を計算して表示します。 |
| 2. | get_race_info(year, month) | 指定された年と月のレース結果を取得します。 ・ランダムな待機時間を設定します。 ・SeleniumとChromeドライバーを使用してブラウザを起動します。 ・レース検索ページにアクセスし、指定された年と月で検索条件を設定します。 ・検索結果のページからレースの詳細ページへのリンクを収集します。 ・収集したリンクを使用して各レースの詳細結果を取得し、データフレームに保存します。 ・取得したレース結果をCSVファイルに保存します。 |
| 3. | search_race(browser, year, month) | 指定された年と月でレースの検索条件を設定します。 ・ランダムな待機時間を設定します。 ・Seleniumを使用してブラウザで要素を操作します。 ・レースのトラックを選択します。 ・開始年・月と終了年・月を設定します。 ・検索ボタンをクリックして検索を実行します。 |
| 4. | make_raceurl_list(browser, link_list) | 検索結果のページからレースの詳細ページへのリンクを収集します。 ・ページのHTMLを取得します。 ・BeautifulSoupを使用してHTMLを解析し、リンクを抽出します。 ・抽出したリンクが特定のキーワードを含まない場合はリストに追加します。 |
| 5. | click_next(browser, count_click_next) | 次のページへの遷移を行います。 ・ページをスクロールして次のページへのリンクを探します。 ・次のページが存在する場合はリンクをクリックします。 |
| 6. | get_detail_raceresult(url) | 指定されたレースの詳細結果を取得します。 ・ランダムな待機時間を設定します。 ・レースの詳細ページにアクセスし、HTMLを取得します。 ・BeautifulSoupを使用してHTMLを解析し、必要な情報を抽出します。 ・抽出した情報をデータフレームに追加します。 ・レースの詳細結果をCSVファイルに保存します。 |
| 7. | combine_raceresult(year, end_month, raceresults_path) | 取得したレース結果のCSVファイルを年ごとに結合します。 ・結合用の空のデータフレームを作成します。 ・指定された年の月ごとにCSVファイルを読み込み、データフレームに結合します。 ・結合したデータフレームを返します。 |
| 8. | その他の関数 retry_request(url, max_retries, retry_delay)、get_parents_name(soup)、get_race_name(), get_race_round(), get_race_date(), get_race_place(), get_race_distance(), get_race_weather(), get_race_condition() |
指定されたURLのHTMLを取得する関数、両親の名前、レース名、ラウンド、レース開催日、などを行います。 |
プログラムの動作環境
動作確認が取れている環境は下記となります。
| OS | Windows 10 Pro |
| CPU | Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz、2208 Mhz、6 個のコア、12 個のロジカル プロセッサ |
| メモリ | 16GB |
| ネット回線 | OCN 光 |
| Python | 3.10.8 |
| 標準ライブラリ | re、time、os、random、datetime、multiprocessing |
| 追加ライブラリ | pandas(1.5.2)、urllib3(1.26.13)、requests(2.28.1)、webdriver-manager(3.8.5)、selenium(4.7.2)、bs4(4.11.1)、tqdm(4.64.1) |
プログラム実行のために用意する入力データ
用意する入力データはありません。
指定した期間のレース結果の情報をnetkeibaから取得します。
プログラム実行の出力結果
プログラムの実行が正常に完了すると、`\data\raceresults`フォルダにnetkeibaから取得したレース結果を保存したCSVファイルが生成されます。
生成されるファイル名:年_1_年_12_raceresults.csv
CSVファイルに含まれるカラムは下記となります。
カラムの内容は前回のカラムと違いはありません。
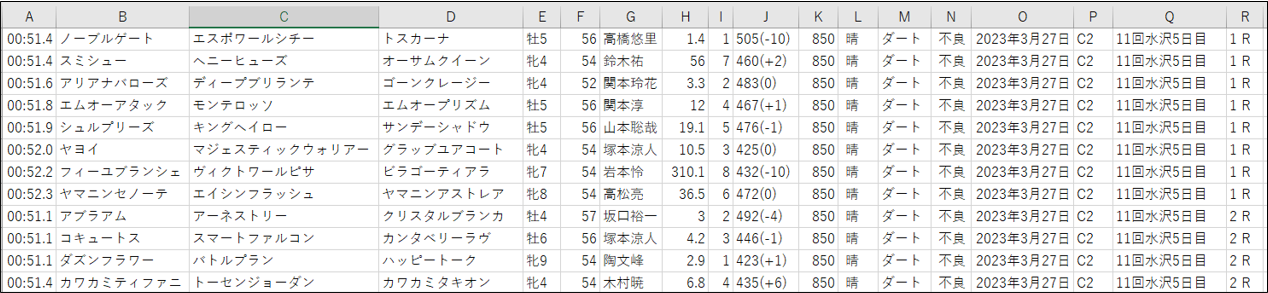
| 列 | カラム名 | 例 |
| A列 | タイム | 00:51.4(分:秒.コンマで表現) |
| B列 | 馬名 | ノーブルゲート(出走馬の名前) |
| C列 | 父親 | エスポワールシチー(出走馬の父親の名前) |
| D列 | 母親 | トスカーナ(出走馬の母親の名前) |
| E列 | 性齢 | 牡5(出走馬の性齢) |
| F列 | 斤量 | 56(騎手の斤量) |
| G列 | 騎手 | 高橋悠里(騎手の名前) |
| H列 | 単勝 | 1.4(レース発送時の単勝オッズ) |
| I列 | 人気 | 1(レース発送時の人気) |
| J列 | 馬体重 | 505(-10)(出走馬の馬体重) |
| K列 | 距離 | 850(レースの距離) |
| L列 | 天候 | 晴(レース当日の天候) |
| M列 | 馬場 | ダード(馬場の情報) |
| N列 | 状態 | 不良(馬場の状態) |
| O列 | 開催日 | 2023年3月27日(レースの開催日) |
| P列 | レース名 | C2(レース名) |
| Q列 | 開催場所 | 11回水沢5日目(レースの開催場所、回数場所日数を含める) |
| R列 | ラウンド | 1 R(数値とRの間には半角スペース有り) |
<生成されたCSVファイルの抜粋>
プログラム実行を行う前の調整項目
このプログラムでは、以下のパラメータを調整できます。
| 変数名 | 設定内容 | 説明 | 調整方法 |
| pool_size | マルチプロセスのプールサイズ(同時実行数) | レース結果の取得を並列化するために使用されるプールのサイズを設定します。デフォルトでは6に設定されています。 | `pool_size`の値を変更して、実行時に使用するプールのサイズを設定します。例えば、`pool_size = 10`とすると、プールサイズが10になります。 |
| start_year_list | 取得を開始する年 | レース結果を取得する範囲の年を設定します。デフォルトでは2021年から2022年までのレース結果を取得します。 | `start_year_list`と`end_year_list`の値を変更して、レース結果を取得する範囲の年を設定します。 |
| end_year_list | 取得を終了する年 |
プールサイズを増やす場合は`pool_size`の値を大きな値に設定することで、より多くのプロセスを同時に実行できます。ただし、CPUのコア数やシステムのリソースに合わせて適切な値を選択する必要があります。
また、`start_year_list`と`end_year_list`変数を調整することで、取得するレース結果の範囲を変更することができます。
注意: パラメータの調整には注意が必要です。十分なリソースがない場合や、過度にプロセスを並列化するとパフォーマンスが低下する場合があります。適切なパラメータ設定には実験と評価が必要です。
プログラム実行の手順
1.プログラムの実行環境にPython3.10.8をインストールしてください。
2.コマンドプロンプトを起動し、下記のコマンドを実行して実行環境の作成を行います。
下記の手順は、Cドライブ直下にget_raceResultsフォルダを作成します。
> mkdir C:\get_raceResults
> cd C:\get_raceResults
> python -m venv env3.実行環境をアクティブにします。
> env\Script\active.bat
(env)C:\get_raceResults>4.追加ライブラリをインストールします。
(env)C:\get_raceResults> pip install beautifulsoup4==4.11.1 bs4==0.0.1 lxml==4.9.2 pandas==1.5.2 requests==2.28.1 selenium==4.7.2 tqdm==4.64.1 urllib3==1.26.13 webdriver-manager==3.8.55.C:\get_raceResults配下に[プログラムのコード]からファイル名を[get_raceResults.py]で保存します。
6.コマンドプロンプトで下記を実行します。
(env)C:\get_raceResults> python get_raceResults.pychromeが自動で起動し、NetkeibaからWebスクレイピングでレース結果のURLの取得を開始します。
以上でプログラム実行の手順は終了です。
プログラム実行の補足
プログラムを実行すると、pool_sizeで指定した数のchromeが起動してきます。
1つのchromeで一ヶ月分のレース結果のURLを取得します。chromeを同時に起動すると、実行環境の負荷が高くなるので、プロセスの起動はランダムの待ち時間を設定して、同時にプロセスが起動しないようにしています。
ランダムの待ち時間を設定しているので、下記のように取得するレース結果の月は順番通りにならないことがありますが、プログラムの実行に問題はありません。
年: 2015 月: 6 で検索条件を設定します
年: 2015 月: 4 で検索条件を設定します
年: 2015 月: 3 で検索条件を設定します
年: 2015 月: 1 で検索条件を設定します
年: 2015 月: 5 で検索条件を設定します
年: 2015 月: 2 で検索条件を設定しますレース結果を取得する過程で、何かしらの理由でレース結果の取得に失敗する場合があります。
その場合は、下記のようなメッセージが表示されます。
父親の名前の取得に失敗しました。 https://db.netkeiba.com/horse/2010101763/
年: 2017 月: 5 のレース情報の取得に失敗しました: https://db.netkeiba.com/race/201750052411/取得に失敗した場合は、その出走馬の情報は記録せず、処理を進めます。
レース情報の取得に失敗した場合も同様で、取得に失敗したら処理を進めます。
プログラム内のエラーハンドリング
下記のエラー処理の方法により、プログラムの実行中にエラーや例外が発生した場合でも、該当のエラーメッセージが表示されます。また、プログラムは続行され、他の処理に移ることができます。
1. URLリクエストのリトライ
`retry_request`関数は、リクエストが失敗した場合に指定された回数だけリトライする機能を持っています。リトライの回数やリトライ間の遅延時間は引数で指定されます。リトライが成功した場合はレスポンスオブジェクトが返されます。
res = retry_request(url, max_retries=5, retry_delay=2)
if res is not None:
# 成功した場合の処理
else:
# 失敗した場合の処理2. レース情報の取得エラー
`get_detail_raceresult`関数では、各レースの詳細情報を取得する際にエラーが発生した場合に特定のメッセージを表示します。エラーが発生した場合、文字列`’failed_to_get_info’`が返されます。
detail_raceresult = get_detail_raceresult(url)
if type(detail_raceresult) == str:
print('年:', year, '月:', month, 'のレース情報の取得に失敗しました:', url)
else:
# 成功した場合の処理3. テーブルデータの取得エラー
`make_raceurl_list`関数では、検索結果のテーブルデータを取得する際にエラーが発生した場合に特定のメッセージを表示します。
table_data = soup.find(class_='nk_tb_common') # 検索結果のテーブルを取得する
if table_data is None:
print("テーブルデータが見つかりません")
else:
# テーブルデータを処理する4. 父親・母親の名前の取得エラー
`get_parents_name`関数では、各出走馬の父親と母親の名前を取得する際にエラーが発生した場合に特定のメッセージを表示します。エラーが発生した場合、文字列`’failed_to_get_b_ml’`が返されます。
parents_name = get_parents_name(soup)
if type(parents_name) == tuple:
b_ml_list = parents_name[0]
b_fml_list = parents_name[1]
else:
print('父親の名前の取得に失敗しました。', link_url)注意点:プロセスの同時実行数
6コアのi7-8750HのCPU環境で、pool_sizeを`12`に設定し、プログラムを実行したところ、chromeの起動に失敗したり、レース結果取得の失敗が頻発する状況になりました。
pool_sizeは、プログラムを事項する端末のCPUコア数を確認し、コア数以上のpool_sizeを設定しないほうがよいです。
<参考>
pool_sizeを`6`に設定した場合のCPUとメモリに使用率は下記でした。
・CPUの使用率:45~60%
・メモリの使用率:600~700MB
chromeの起動時に一時的にCPU使用率が60%くらいになりますが、レース結果を取得中のCPU使用率は45~50%でした。
プログラムのコード
# netkeibaから過去のレース情報を取得する
# 呼び出し元:無し
#
# 取得したデータは、./data/raceresults/に指定した西暦_1_指定した西暦_12_raceresults.csvを出力する
# 西暦を指定する箇所は49行目のyearのリストに文字列として西暦を追加する
# 例) 指定した西暦が2020年,2021年,2022年の場合に出力するCSVファイル
# 2020_1_2020_12_raceresults.csv
# 2021_1_2021_12_raceresults.csv
# 2022_1_2022_12_raceresults.csv
#
# 本プログラムはマルチプロセスで動作する
# マルチプロセスのプール数(同時実行数)を調整するためには、pool_sizeの値を変更する
# 調整箇所
# main関数内のpool_size
#
# netkeibaから取得するレース情報の開始と終了を指定する
# 調整箇所
# 1. main関数内のstart_year_list
# 2. main関数内のend_year_list
#
# マルチプロセスで処理を一気に開始すると端末に負荷が掛かり、処理でエラーが発生する場合がある
# レース情報を取得する箇所でランダムの待ち時間を設定している
# 調整箇所
# 1. get_race_info関数内のtime.sleep
# 2. search_race関数内のtime.sleep
#
# seleniumの動作で描画待ちの秒数を手動で設定しているので、実行環境に応じて調整する必要がある
# 調整箇所
# 1. main関数内のbrowser.implicitly_waitの数値
# 2. search関数内のtime.sleepの数値
# 3. click_next関数内のtime.sleepの数値
# ライブラリの読み込み
import pandas as pd
import urllib
import requests
import re
import time
import os
import random
import datetime
from multiprocessing import Pool
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from bs4 import BeautifulSoup
# プログレスバーを表示するためのライブラリを読み込む
from tqdm import tqdm
# メイン処理
# 引数:無し
# 戻値:無し
def main():
# マルチプロセスのプール数を設定する
pool_size = 6
# プログラムの開始時刻を取得する
start_time = time.time()
# 現在の日付を取得
current_date = datetime.date.today()
# 実行日の月の前月までを実行する
end_month = current_date.month - 1
end_year = current_date.year
# 実行日の月が1月の場合、前年の12月までを実行する
if end_month == 0:
end_month = 12
end_year -= 1
# レース結果取得の始まりと終わりの年を設定する
start_year_list = 2018
end_year_list = 2020
# 取得する年のリストを作成する
if end_year_list == current_date.year:
year_list = [str(year) for year in range(start_year_list, end_year + 1)]
else:
year_list = [str(year) for year in range(start_year_list, end_year_list + 1)]
# 各年の各月のレース結果を取得する
for year in year_list:
year_month = []
if year == str(end_year):
months = range(1, end_month + 1)
else:
months = range(1, 13)
year_month.extend([(year, str(month)) for month in months])
# マルチプロセスでレース結果を取得する関数を呼び出す
with Pool(pool_size) as pool:
pool.starmap(get_race_info, year_month)
# 取得したレース結果のパス
raceresults_path = './data/raceresults/'
# 取得したレース結果を年ごとに結合する
if year == str(end_year):
df_combined_data = combine_raceresult(year, end_month, raceresults_path)
else:
df_combined_data = combine_raceresult(year, 12, raceresults_path)
# 結合したデータをCSVファイルに保存する
csv_combined_data_path = raceresults_path + str(year) + '_1_' + str(year) + '_12_raceresults.csv'
df_combined_data.to_csv(csv_combined_data_path, encoding='cp932', header=False, index=False, errors='ignore')
# プログラムの実行時間を表示する
run_time = time.time() - start_time
print('実行時間:{:.2f}秒'.format(run_time))
# レース情報を取得する
# 引数:レース情報を取得する西暦:str、月:str
# 戻値:無し
def get_race_info(year, month):
# ランダム待ち
sec = random.uniform(1, 50)
time.sleep(sec)
# chrome起動時のエラーを消す
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches', ['enable-logging'])
# webdriver_managerで最適なchromeのバージョンをインストールして設定する
browser = webdriver.Chrome(ChromeDriverManager().install(), options=chrome_options)
# 競馬データベースを開く
browser.get('https://db.netkeiba.com/?pid=race_search_detail')
browser.implicitly_wait(20) # 指定した要素が見つかるまでの待ち時間を20秒と設定する
search_race(browser, year, month) # 検索条件を設定して検索する
link_list = [] # リンクページのURLリスト
no_click_next = 0 # 0:次のページ無し、1:次のページ有り
count_click_next = 0 # 0:検索結果の1ページ目、1以上:検索結果の2ページ目以上
while no_click_next == 0:
# レース結果のリンクページのURLを取得する
link_list = make_raceurl_list(browser, link_list)
# 「次」をクリックし、「次」の有無とクリックした回数を返す
no_click_next, count_click_next = click_next(browser, count_click_next)
# chromeを閉じる
browser.quit()
# レース結果を保存するデータフレームを用意する
df_race_result = pd.DataFrame()
# レース結果のリンクページにアクセスして、レース結果を取得する
# 日本レース以外のレース結果は取得しない
# 日本以外のレースのリンクページには、/race/2022H1a00108/のようにアルファベットが含まれている
# isdecimalで文字列が数字のみかを判定している
print('年:', year, '月:', month, 'のレース結果の詳細を取得します')
for url in tqdm(link_list):
if url.split('/')[-2].isdecimal():
detail_raceresult = get_detail_raceresult(url)
if type(detail_raceresult) == str:
print('年:', year, '月:', month, 'のレース情報の取得に失敗しました:', url)
else:
df_race_result = pd.concat([df_race_result, detail_raceresult], axis=0)
# CSVにレース結果を保存する
# レース結果のCSVを保存するフォルダが無ければ作成する
print(year, '年', month, '月のレース結果のCSVファイルを作成します。')
os.makedirs('./data/raceresults', exist_ok=True)
file_name = str(year) + '_' + str(month) + '_' + str(year) + '_' + str(month) + '_raceresults.csv'
file_path = './data/raceresults/' + file_name
df_race_result.to_csv(file_path, encoding='cp932', header=False, index=False, errors="ignore")
# 検索条件を設定して検索する
# 引数:webdriverオブジェクト:webdriver、年:str、月:str
# 戻値:無し
def search_race(browser, year, month):
print('年:', year, '月:', month, 'で検索条件を設定します')
# ランダム待ち
sec = random.uniform(1, 50)
time.sleep(sec)
# 競争種別で「芝」と「ダート」にチェックを入れる
elem_check_track_1 = browser.find_element(By.ID, value='check_track_1')
elem_check_track_2 = browser.find_element(By.ID, value='check_track_2')
elem_check_track_1.click()
elem_check_track_2.click()
# 期間を2021年から2022年に設定する
elem_start_year = browser.find_element(By.NAME, value='start_year')
elem_start_year_select = Select(elem_start_year)
elem_start_year_select.select_by_value(year)
# 月を指定する場合は、select_by_valueで月数を指定する
elem_start_month = browser.find_element(By.NAME, value='start_mon')
elem_start_month_select = Select(elem_start_month)
elem_start_month_select.select_by_value(month)
elem_end_year = browser.find_element(By.NAME, value='end_year')
elem_end_year_select = Select(elem_end_year)
elem_end_year_select.select_by_value(year)
# 月を指定する場合は、select_by_valueで月数を指定する
elem_end_month = browser.find_element(By.NAME, value='end_mon')
elem_end_month_select = Select(elem_end_month)
elem_end_month_select.select_by_value(month)
# 画面を下にスクロールする
browser.execute_script('window.scrollTo(0, 400);')
# 表示件数を100件にする
elem_list = browser.find_element(By.NAME, value='list')
elem_list_select = Select(elem_list)
elem_list_select.select_by_value('100')
# 検索をクリック(submit)する
elem_search = browser.find_element(By.CLASS_NAME, value='search_detail_submit')
time.sleep(4)
elem_search.submit()
# 取得したHTMLからレース結果のURLを抽出し、URLリストに追加してURLリストを作成する
# 引数:webdriver、リンクページのURLリスト
# 戻値:リンクページのURLリスト:list
def make_raceurl_list(browser, link_list):
# print('取得したHTMLからレース結果のURLを抽出します')
html = browser.page_source.encode('utf-8') # UTF-8でHTMLを取得する
soup = BeautifulSoup(html, 'html.parser') # 検索結果をbeautifulSoupで読み込む
try:
table_data = soup.find(class_='nk_tb_common') # 検索結果のテーブルを取得する
if table_data is None:
# エラーが発生した場合の処理
print("テーブルデータが見つかりません")
else:
for element in table_data.find_all('a'):
url = element.get('href') # リンクページを取得する
# リンクページがjavascriptの場合は、次のリンクページの処理に移る
if 'javascript' in url:
continue
# リンクページの絶対URLを作成する
link_url = urllib.parse.urljoin('https://db.netkeiba.com', url)
# レース結果のみを抽出する
# レース結果のURLは'https://db.netkeiba.com/rase/yyyymmddXXXX'となる
# 馬情報のURLは'https://db.netkeiba.com/horse/yyyymmddXXXX'
# 騎手情報のURLは'https://db.netkeiba.com/jockey/result/recent/'
# レース結果以外のリンクページを除外するための単語リストを用意する
word_list = ['horse', 'jockey', 'result', 'sum', 'list', 'movie']
tmp_list = link_url.split('/') # リンクページのURLを'/'で分割する
and_list = set(word_list) & set(tmp_list) # word_listとtmp_listを比較し、一致している単語を抽出する
# 一致している単語が0のリンクページのURLのリストを作成する
if len(and_list) == 0:
link_list.append(link_url)
except Exception as e:
print(f"エラーが発生しました: {e}")
return link_list
# print('URLを抽出しました')
return link_list
# 画面下にスクロールして「次」をクリックする
# 引数:webdriverオブジェクト:webdriver
# 戻値:「次」の有無(1/0):int、「次」をクリックした回数:int
def click_next(browser, count_click_next):
# 画面を下にスクロールする
browser.execute_script('window.scrollTo(0, 2500);')
time.sleep(3)
# 次をクリックする
# 検索1ページ目のxpathは2ページ以降とは異なるため、count_click_nextで
# 検索1ページ目なのかを判定している
if count_click_next == 0:
xpath = '//*[@id="contents_liquid"]/div[2]/ul[1]/li[14]/a/span/span'
elem_search = browser.find_element(By.XPATH, value=xpath)
elem_search.click()
no_click_next = 0
else:
# 検索最後のページで次をクリックしようとすると例外処理が発生する
# exceptで例外処理を取得し、no_click_nextに1を代入する
try:
xpath = '//*[@id="contents_liquid"]/div[2]/ul[1]/li[14]/a/span/span'
elem_search = browser.find_element(By.XPATH, value=xpath)
time.sleep(2)
elem_search.click()
no_click_next = 0
except:
print('次のページ無し')
no_click_next = 1
count_click_next += 1 # ページ数を判別するためのフラグに1を加算する
return no_click_next, count_click_next
# レース結果の詳細を取得する
# 引数:取得するレース結果のURL:str
# 戻値:取得して整形したレース結果の情報:Dataframe
def get_detail_raceresult(url):
# 指定したURLからデータを取得する
res = retry_request(url, max_retries=5, retry_delay=2)
if res is not None:
soup = BeautifulSoup(res.content, 'lxml') # content形式で取得したデータをhtml形式で分割する
else:
# リトライ回数を超えても成功しなかった場合の処理
print("リクエスト失敗:", url)
# 各出走馬の両親の名前を取得する
parents_name = get_parents_name(soup)
if type(parents_name) == tuple:
b_ml_list = parents_name[0]
b_fml_list = parents_name[1]
else:
return 'failed_to_get_info'
# レース名を取得する
race_name = get_race_name(soup)
# ラウンド数を取得する
race_round = get_race_round(soup)
# 開催日を取得する
race_date = get_race_date(soup)
# 開催場所を取得する
race_place = get_race_place(soup)
# レースの距離を取得する
race_distance = get_race_distance(soup)
# 開催場所の天候を取得する
race_weather = get_race_weather(soup)
# 開催場所の馬場状態を取得する
race_condition = get_race_condition(soup)
# tableデータを抽出する
tables = soup.find('table', attrs={'class': 'race_table_01'})
tables = tables.find_all('tr')
# レース情報/結果を取得する
df_raceresults = pd.DataFrame()
for table in tables[1:]:
raceresults_row = table.text.split('\n')
df_raceresults_row = pd.Series(raceresults_row)
df_raceresults = pd.concat([df_raceresults, df_raceresults_row], axis=1)
# 学習に必要な情報のみを抽出する
# 着順:要素No.1、馬名:要素No.5、性齢:要素No.7、斤量:要素No.8、騎手:要素No.10、
# タイム:要素No.12、上り:要素No.21、単勝:要素No.23、人気:要素No.24、馬体重:要素No.25の情報を抽出する
df_raceresults_extracted_columns = pd.DataFrame()
# レース結果のテーブルが異なることがあるので、必要なカラム列の番号をそれぞれで用意する
columns_list1 = [1, 5, 7, 8, 10, 12, 21, 23, 24, 25]
columns_list2 = [1, 5, 7, 8, 10, 12, 18, 20, 21, 22]
# テーブルの状態次第で必要なカラム列の番号を変える
# 17列は「通過」の情報が記録されているが、テーブルによって'**'となっている場合となっていない場合の2種類のテーブルが存在している
# 17列が'**'となっている場合は、カラム列はcolumns_list1を使用する
df_speed_index = df_raceresults.iloc[17]
if df_speed_index.values[0] == '**':
for i in columns_list1:
df_extracted_columns = df_raceresults.iloc[i]
df_raceresults_extracted_columns = pd.concat([df_raceresults_extracted_columns,
df_extracted_columns], axis=1)
else:
for i in columns_list2:
df_extracted_columns = df_raceresults.iloc[i]
df_raceresults_extracted_columns = pd.concat([df_raceresults_extracted_columns,
df_extracted_columns], axis=1)
# カラム名を設定する
tmp = ['着順', '馬名', '性齢', '斤量', '騎手', 'タイム', '上り', '単勝', '人気', '馬体重']
df_columns = pd.Series(tmp)
df_raceresults_extracted_columns.columns = df_columns # index名を設定する
# 整形したレース情報を保存するデータフレームを用意する
df_reshaped_raceresults = pd.DataFrame()
try:
# 距離、天候、馬場、状態、開催日、レース名、開催場所、ラウンド、父親、母親の列を追加する
df_raceresults_extracted_columns['距離'] = race_distance
df_raceresults_extracted_columns['天候'] = race_weather[1]
df_raceresults_extracted_columns['馬場'] = race_condition[0]
df_raceresults_extracted_columns['状態'] = race_condition[1]
df_raceresults_extracted_columns['開催日'] = race_date
df_raceresults_extracted_columns['レース名'] = race_name
df_raceresults_extracted_columns['開催場所'] = race_place
df_raceresults_extracted_columns['ラウンド'] = race_round
df_raceresults_extracted_columns['父親'] = b_ml_list
df_raceresults_extracted_columns['母親'] = b_fml_list
# 説明変数として使用しない列を削除する
df_raceresults_extracted_columns.drop(['着順', '上り'], axis=1, inplace=True)
# 目的変数にするタイムを1列に変更する
df_reshaped_raceresults = df_raceresults_extracted_columns.reindex(columns=['タイム', '馬名', '父親', '母親',
'性齢', '斤量', '騎手', '単勝',
'人気', '馬体重', '距離', '天候',
'馬場', '状態', '開催日', 'レース名',
'開催場所', 'ラウンド'])
except:
print('レース情報を取得できませんでした')
return df_reshaped_raceresults
# レースに出場する出走馬の両親の情報を取得する
# 引数:レース情報のhtml:tag
# 戻値:各出走馬の父親、母親の名前:list
def get_parents_name(soup):
race_table_data = soup.find(class_='race_table_01 nk_tb_common') # 検索結果のテーブルを取得する
b_ml_list = [] # 各出走馬の父親の名前を保持するリスト
b_fml_list = [] # 各出走馬の母親の名前を保持するリスト
for element in race_table_data.find_all('a'):
url = element.get('href') # リンクページを取得する
# リンクページがjavascriptの場合は、次のリンクページの処理に移る
if 'javascript' in url:
continue
# リンクページの絶対URLを作成する
link_url = urllib.parse.urljoin('https://db.netkeiba.com', url)
# 出走馬の情報のみを抽出する
# 出走馬の情報のURLは'https://db.netkeiba.com/horse/yyyyXXXXXXX'となる
# 出走馬の情報以外のリンクページを除外するための単語リストを用意する
word_list = ['jockey', 'result', 'sum', 'list', 'movie',
'premium', 'horse_training', 'horse_comment']
# 出走馬の情報以外のリンクページだった場合、countを+1する
count = 0
for word in word_list:
if word in link_url:
count += 1
# 一致している単語が0のリンクページのURLのリストを作成する
if count == 0:
# 血統情報を取得する
res = retry_request(link_url, max_retries=5, retry_delay=2)
if res is not None:
soup_blood_table = BeautifulSoup(res.content, 'lxml')
else:
# リトライ回数を超えても成功しなかった場合の処理
print('リクエスト失敗:', link_url)
# 父親の名前を取得する
elements_b_ml = soup_blood_table.find_all(class_='b_ml')
if len(elements_b_ml) == 0:
print('父親の名前の取得に失敗しました。', link_url)
return 'failed_to_get_b_ml'
element_b_ml = elements_b_ml[0].text.replace('\n', '')
b_ml_list.append(element_b_ml)
# 母親の名前を取得する
elements_b_fml = soup_blood_table.find_all(class_='b_fml')
if len(elements_b_ml) == 0:
print('母親の名前の取得に失敗しました。', link_url)
return 'failed_to_get_b_fml'
element_b_fml = elements_b_fml[1].text.replace('\n', '')
b_fml_list.append(element_b_fml)
return b_ml_list, b_fml_list
# 指定されたURLのデータを取得する
# 引数: URL:str,リトライ回数:int,リトライ待ち時間:int
# 戻値: 取得に成功したら指定されたURLのデータ:htmlタグ,取得に失敗したらNone:None
def retry_request(url, max_retries=3, retry_delay=1):
retries = 0
while retries < max_retries:
try:
res = requests.get(url)
return res
except requests.exceptions.RequestException:
# リクエストエラーが発生した場合はリトライする
retries += 1
time.sleep(retry_delay)
return None
# レース名を取得する
# 引数:レース情報のhtml:tag
# 戻値:レース名:str
def get_race_name(soup):
race_name = soup.find_all('h1')
race_name = race_name[1].text
return race_name
# ラウンド数を取得する
# 引数:レース情報のhtml:tag
# 戻値:レースのラウンド:str
def get_race_round(soup):
race_round = soup.find('dl', attrs={'class': 'racedata fc'})
race_round = race_round.find_all('dt')
race_round = race_round[0].text
race_round = race_round.replace('\n', '')
return race_round
# 開催日を取得する
# 引数:レース情報のhtml:tag
# 戻値:開催日:str
def get_race_date(soup):
# 開催日を取得する
race_base_info = soup.find('p', attrs={'class': 'smalltxt'})
rase_base_info_text = race_base_info.text.replace(u'\xa0', u' ')
words = rase_base_info_text.split(' ')
race_date = words[0]
return race_date
# 開催場所を取得する
# 引数:レース情報のhtml:tag
# 戻値:開催場所:str
def get_race_place(soup):
race_base_info = soup.find('p', attrs={'class': 'smalltxt'})
rase_base_info_text = race_base_info.text.replace(u'\xa0', u' ')
words = rase_base_info_text.split(' ')
race_place = words[1]
return race_place
# レースの距離を取得する
# 引数:レース情報のhtml:tag
# 戻値:レースの距離:int
def get_race_distance(soup):
race_info = soup.find('diary_snap_cut')
race_info_text = race_info.text.replace(u'\xa0', u' ') # ノーブレークスペースを削除
race_info_text = race_info.text.replace(u'\xa5', u' ') # Webページの文字参照を削除
words = race_info_text.split('/')
words[0] = re.sub(r'2周', '', words[0]) # レース情報の'2周'を空文字に置き換える
race_distance = int(re.sub(r'\D', '', words[0])) # レース距離だけを取り出してint型で保存する
return race_distance
# 開催場所の天候を取得する
# 引数:レース情報のhtml:tag
# 戻値:開催場の天候:list
def get_race_weather(soup):
race_info = soup.find('diary_snap_cut')
race_info_text = race_info.text.replace(u'\xa0', u' ') # ノーブレークスペースを削除
race_info_text = race_info.text.replace(u'\xa5', u' ') # Webページの文字参照を削除
words = race_info_text.split('/')
race_weather = words[1].split(':')
return race_weather
# 開催場所の馬場状態を取得する
# 引数:レース情報のhtml:tag
# 戻値:開催場所の馬場状態:list
def get_race_condition(soup):
race_info = soup.find('diary_snap_cut')
race_info_text = race_info.text.replace(u'\xa0', u' ') # ノーブレークスペースを削除
race_info_text = race_info.text.replace(u'\xa5', u' ') # Webページの文字参照を削除
words = race_info_text.split('/')
race_condition = words[2].split(':')
return race_condition
# 取得したレース結果を結合する。結合済みのCSVファイルは使用しないので削除する。
# 引数: 年:int,月:int,結合するCSVファイルのパス:str
# 戻値: 結合したCSVファイルのデータフレーム:df
def combine_raceresult(year, end_month, raceresults_path):
# 取得したレース結果を結合するためのデータフレーム
df_combined_data = pd.DataFrame()
for i in range(end_month, 0, -1):
raceresults_csv_path = raceresults_path + str(year) + '_' + str(i) + '_' + str(year) + '_' + str(
i) + '_raceresults.csv'
is_csv_file = os.path.isfile(raceresults_csv_path)
if is_csv_file:
df_read_csv = pd.read_csv(raceresults_csv_path, header=None, encoding='shift-jis')
df_combined_data = pd.concat([df_combined_data, df_read_csv], ignore_index=True)
# 結合したCSVファイルは削除する
os.remove(raceresults_csv_path)
return df_combined_data
if __name__ == "__main__":
main()次回、行いたいこと
両親の情報を含めたレース情報で学習モデル作成に着手したいと思います。
競馬予測プログラム自体が肥大化、複雑化してきたので、メンテナンスことを考えてリファクタリングを考えています。


コメント