
はじめに
前回取得したデータでAIモデルを作成する前に、データの状態を確認します。
欠損値や異常値の有無を確認し、除外あるいは補完を行います。また、各データの統計情報と相関係数をCSVファイルに保存し、のちほど確認できるようにしておきます。
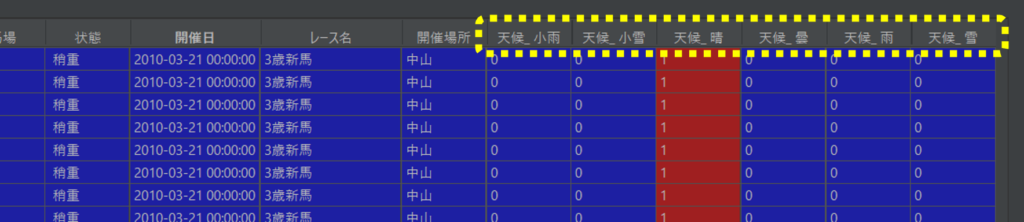
取得したデータには天候(小雨、雨、曇、晴、雪、小雪)、状態(良、重、ダード、芝)が含まれています。One-Hotエンコーディングを天候や状態に適用することで、天候であれば小雨、雨、曇、などで新しい列を作成して該当する項目に1、それ以外の項目には0を割り当てます。
天候にOne-Hotエンコーディングを適用した場合は下記のようになります。
One-Hotエンコーディング適用前

One-Hotエンコーディング適用後
プログラムの概要
| 該当行 | 概要 |
| 1~4 | ライブラリの読み込み |
| 6~12 | レース結果のCSVファイルを読み込みカラム名を設定する |
| 14~17 | 各列の型、要約統計量、各列の欠損数を確認する |
| 19~24 | 一部でも欠損している行、馬体重が’計不’になっている行を削除する |
| 29~40 | 開催日の型をobjectからdatetime64に変換する タイムのmm:ssの表記をssに変換する(01:22→82) |
| 42~50 | 馬体重の”()”を削除して現在の体重のみを取得する |
| 52~55 | 一部の値は’2,010.0’となっているので、’2010’に変換する |
| 58~63 | One-Hotエンコーディングを行う関数 |
| 66~68 | 騎手と馬名のユニーク数/出現数を保存する |
| 70~86 | 馬名、天候、性齢、状態、馬場、騎手でOne-Hotエンコーディングを実行する |
| 88~90 | One-Hotエンコーディング後の各列の最大値/最小値/平均/標準偏差/データ数、相関係数をCSVに保存する |
| 92~95 | 各列同士の相関係数をヒートマップで表示する |
作成したプログラム
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
# レース結果を読み込む
df_race_result = pd.read_csv('./2010_1_2010_12_レースの結果.csv', encoding='cp932')
# カラム名を設定する
df_race_result.columns = ['タイム', '馬名', '性齢', '斤量', '騎手', '単勝',
'人気', '馬体重', '距離', '天候', '馬場', '状態',
'開催日', 'レース名', '開催場所']
# 各列の型、要約統計量、各列の欠損数を確認する
print(df_race_result.dtypes)
print(df_race_result.describe())
print(df_race_result.isnull().sum())
# 欠損している行を削除する
df_race_result = df_race_result.dropna()
# 馬体重が'計不'になっている行を削除する
drop_target = df_race_result.index[(df_race_result['馬体重'] == '計不')]
df_race_result = df_race_result.drop(drop_target)
# 行を削除したのでindexをリセットする
df_race_result = df_race_result.reset_index(drop=True)
# 開催日の型をobjectからdatetime64に変換する
df_race_result['開催日'] = pd.to_datetime(df_race_result['開催日'], format='%Y年%m月%d日')
# 分秒の表記を秒に変換する
time_list = []
df_time = df_race_result['タイム'].str.split(':')
for i in df_time:
times = float(i[0]) * 60 + float(i[1])
time_list.append(times)
df_times_list = pd.DataFrame(time_list)
df_race_result['タイム'] = df_times_list
# 馬体重の()を削除して現在の体重を取得する
weight_list = []
df_weight = df_race_result['馬体重'].str.split('(')
for i in df_weight:
weight = float(i[0])
weight_list.append(weight)
df_weight_list = pd.DataFrame(weight_list)
df_race_result['馬体重'] = df_weight_list
# 単勝の型をobjectからfloatに変換する
# 一部の値は'2,010.0'となっているので、'2010'に変換する
df_race_result = df_race_result.replace('2,010.0', '2010')
df_race_result['単勝'] = df_race_result['単勝'].astype(float)
# One-Hotエンコーディングを行う関数
def one_hot_enc(df, column):
df_dummy = pd.get_dummies(df[column], prefix=column) # get_dummiesでone hot encodingを取得する
df_drop = df.drop([column], axis=1) # 元列を削除する
df = pd.concat([df_drop, df_dummy], axis=1) # df_dropとdf_dummyを横結合する
return df
# 馬名、騎手のユニーク数,出現数をカウントする
df_race_result['馬名'].value_counts().to_csv('./馬名.csv', encoding='cp932', errors='ignore')
df_race_result['騎手'].value_counts().to_csv('./騎手.csv', encoding='cp932', errors='ignore')
# 馬名をone_hot_encodingする
# df_race_result = one_hot_enc(df_race_result, '馬名')
# 天候をone_hot_encodingする
df_race_result = one_hot_enc(df_race_result, '天候')
# 性齢をone_hot_encodingする
df_race_result = one_hot_enc(df_race_result, '性齢')
# 状態をone_hot_encodingする
df_race_result = one_hot_enc(df_race_result, '状態')
# 馬場をone_hot_encodingする
df_race_result = one_hot_enc(df_race_result, '馬場')
# 騎手をone_hot_encodingする
df_race_result = one_hot_enc(df_race_result, '騎手')
# 各列の最大値、最小値、平均、標準偏差、データ数、相関係数を保存する
df_race_result.describe().to_csv('./要約統計量.csv', encoding='cp932', errors='ignore')
df_race_result.corr().to_csv('./相関係数.csv', encoding='cp932', errors="ignore")
# 各列同士の相関係数をヒートマップで表示する
fig, ax = plt.subplots(figsize=(12, 12))
sns.heatmap(df_race_result.corr(), vmax=1, vmin=-1, center=0, annot=True)
plt.show()プログラムの実行結果
4つのCSVファイルと各列同士の相関係数のヒートマップを出力します。
出力されるCSVファイルは以下の4つなります。
| CSVファイル名 | 概要 |
| 馬名.csv | 馬ごとの出走数 |
| 騎手.csv | 騎手ごとの騎乗数 |
| 要約統計量.csv | 最大値、最小値、平均、標準偏差、データ数 |
| 相関係数.csv | 各列同士の相関係数 |
馬名と騎手のCSVファイルの一部
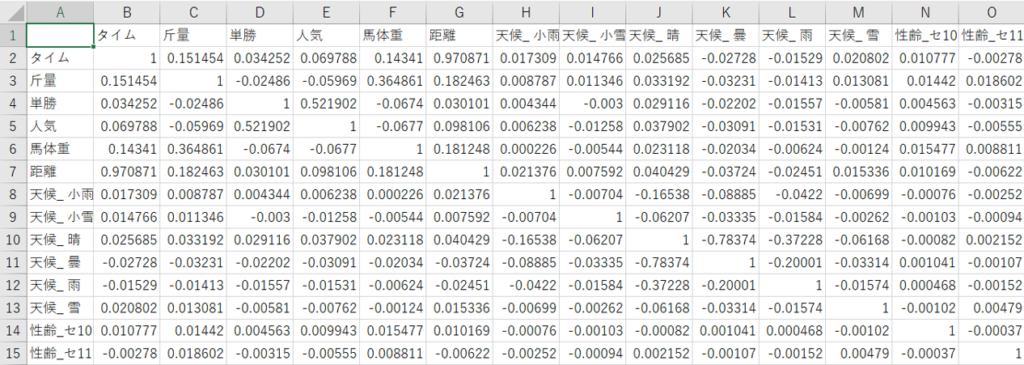
相関係数のCSVファイルの一部
要約統計量のCSVファイルの一部

ヒートマップ

プログラム作成時にハマったところ
馬名でOne-Hotエンコーディングすると処理が終わらない
2010年1月~12月のレースで出場した馬頭数は、20,891でした。
馬名でOne-Hotエンコーディングすると、メモリの使用容量が99%になり処理が終わりませんでした。71行目の馬名でのOne-Hotエンコーディングはコメントアウトしています。
取得したデータの確認結果
取得した2010年1月~12月のレース情報で、欠損が存在する列と、欠損数(行数)は以下でした。
- タイム列:1978行
- 単勝列:18行
- 人気列:1461行
- 馬体重:40行
タイム列が欠損している情報は、単勝列や人気列も欠損していることが多く、出走を取りやめた可能性があったので、データを補完するのではなく行ごと削除しました。馬体重列の値が「計不」となっている行がありました。この行もデータを補完するのではなく行ごと削除しました。
作成するAIモデルの目的変数は「タイム」にする予定です。「タイム」と相関関係が高いのは0.97の「距離」でした。この結果は予想通りでした。次に相関関係が高いのは「斤量」と「馬体重」でした。ただ、それぞれの相関係数は0.15、0.14でほとんど関係はなさそうです。天候、馬場、状態、騎手などの相関係数は、ほぼ0でした。
次回、試すこと
整形したデータとxgboostとligthgbmで、タイムを予測するAIモデルを作成してみます。

コメント
ModuleNotFoundError: No module named ‘distutils’
というエラー表記が出ます。これはどのように対処すればよろしいでしょうか?
distutilsモジュールは「Pythonモジュールと拡張のビルド、配布、インストールをサポートするためのパッケージ」と認識しています。
Pythonのコード実行で、distutilsモジュールは直接的には関係ないはずです。
また、Python3.12からは廃止になったモジュールです。
こちらの実行環境を確認しましたが、distutilsモジュールは追加していませんでした。
mrさんの実行環境固有の事象と思われますが、対処案を考えてみました。
■対処案1:distutilsモジュールをインストールする
UbuntuやDebian系の環境であれば下記でインストールする
sudo apt-get install python3-distutilsFedoraやRed Hat系の環境であれば下記でインストールする
sudo dnf install python3-distutils■対処案2:Pythonの実行環境を再構築する
pythonコマンドのvenvを用いて、Pythonの実行環境を再構築してみてください。
venvを用いれば、複数のPython実行環境を用意できます。
はじめまして。
Pythonの学習をしながら、参考にさせていただいています。
win環境においてMRさんと同じエラーに合いましたがsetuptoolsのインストールで解決しました。
(参考:https://qiita.com/pitao/items/1740a62ddee797aed807)
続いて、下記エラーで悩んでおります。
ValueError: could not convert string to float: ‘ドリームラヴァー’
ご助言いただけますと助かります。
レース結果のCSVファイルのカラム(列の並び)が想定と異なっている状態かもしれません。
エラーの内容を見るに、文字列「ドリームラヴァー」を浮動小数点数(float)に変換しようとしています。
浮動小数点数(float)の変換処理は下記3個所で実施しています。
1. 32行目の「分秒の表記を秒に変換する」
2. 42行目の「馬体重の()を削除して現在の体重を取得する」
3. 52行目の「単勝の型をobjectからfloatに変換する」
レース結果のCSVファイルのカラムの並びは、「タイム」→「馬名」→「性齢」→省略です。
「タイム」の列に「馬名」が入っている可能性があります。
取得したレース結果のCSVファイルを開いて「ドリームラヴァー」の行を確認し、カラムの内容が他の行と同類の内容かを確認してみてください。
sakuraterさま
ご助言ありがとうございます。
vs codeのデバッグで流してみたところ、90行目でエラーとなっている状況です。
=================================
例外が発生しました: ValueError
could not convert string to float: ‘ドリームラヴァー’
File “C:\Users\***\OneDrive\デスクトップ\python\***\***.py”, line 90, in
df_race_result.corr().to_csv(‘./相関係数.csv’, encoding=’cp932′, errors=”ignore”)
^^^^^^^^^^^^^^^^^^^^^
ValueError: could not convert string to float: ‘ドリームラヴァー’
=================================
まだ理解が浅く、的外れな質問かもしれないのですが、71行目(馬名)がコメントアウトされているのは故意でしょうか??
また、Windows PowerShellのバージョンが関係する可能性はありますか?
Windows Terminalに表示される「新機能と改善のために最新の PowerShell をインストールしてください!」のメッセージをずっとスルーし続けています(現:5.1.22621.2506)
連日すみません、よろしくお願いします。
エラー内容を確認しました。
エラーとなっているのは、レース結果内容の相関をCSVファイルに出力する箇所であることを理解しました。
71行目をコメントアウトを外している、と推測しました。
71行目にコメントアウトを付けて実行してみてください。
また、71行目にコメントアウトを付けている理由については、頂いた質問の回答に記載しました。
■質問1:71行目は意図的にコメントアウトしているのか?
はい、意図的にコメントアウトしています。
2023年に出馬した頭数は、おおよそ1万2千頭です。他の年もおそらく同数程度、出馬しているはずです。
1万2千頭の馬名を含めた相関を出力しようとすると、計算にかなりのメモリ容量とCPU使用を必要とします。
そのため、71行名はコメントアウトしています。
■質問2:Windows PowerShellのバージョンが関係する可能性はありますか?
関係していないと思います。
PowerShellのバージョンが古いことが原因でPythonプログラムにエラーが発生することはないはずです。
PowerShellは単にPythonプログラムを実行するための仮想環境を呼び出しているだけで、
Pythonプログラム実行自体は、Pythonの仮想環境(ブログだとvenv)で実行されます。
PowerShellのバージョンで、Pythonプログラム自体の実行には影響しないはずです。
sakuraterさま
71行目については本文にも記載がありましたね、大変失礼しました。
>>71行目にコメントアウトを付けて実行してみてください。
結果は変わりませんでした。
調べてみたところ、pandasのバージョンによって”numeric_only=True”を明記しないとエラーとなる場合があることがわかりました。
(参考:https://www.relief.jp/docs/python-in-excel-libs-version.html)
記事を参考にさせていただきながら、もう少し勉強してみます。