
はじめに
fbprophetのパラメータを調整することで、株価の予測精度を向上させることができました。
今回は、特徴量に自己回帰データ、外部データを追加することで株価の予測精度の向上となるかを検証してみました。
予測検証の概要は下記の通りです。
- 予測する株価:7203(トヨタ)の終値
- 予測に使用する訓練データの期間:2018/1/4~2020/11/10
- 予測モデルを評価するデータ期間:2020/11/11~2020/12/30
- 予測に使用する特徴量:訓練データ期間の終値と自己回帰データ、外部データ
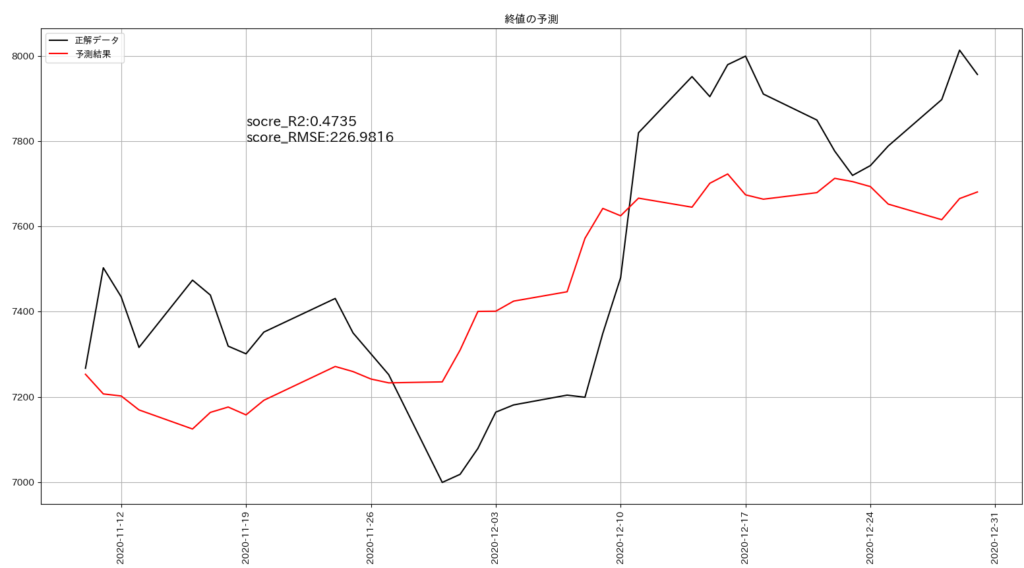
結論としては、予測に使用する特徴量が「終値のみ」の場合と比較して、株価の予測精度を向上させることができました。
| 特徴量 | R2 | RMSE |
| 終値のみ | 0.0366 | 307.0447 |
| 終値+自己回帰データ+外部データ | 0.4735 | 226.9816 |
※R2は1に近いほど精度は高く、RMSEは0に近いほど精度が高いことを示す。
正解データと予測結果を比較したグラフは下記の通りです。
終値のみの場合と比較して、正解データに近い予測結果を出すことができました。
特徴量に追加する外部データ
外部データは下記の4つの終値としています。
- 円ドル為替(JPYUSD)
- ダウ平均(DJI)
- NASDAQ総合(IXIC)
- 日経平均(N225)
外部データは、前回作成したプログラムで取得し、CSVファイルとして保存しておきます。
特徴量に追加するその他のデータ
特徴量に追加するその他のデータとして、下記の2つを追加しました。
- 過去の終値(自己回帰)
- 過去の終値の移動平均
過去の終値が、現在の終値に影響している可能性があるので、過去の終値を特徴量に追加しました。また、過去の終値の移動平均を追加してみました。
データを組み合わせて特徴量を作成する
用意したデータの組み合わせで、予測精度が変わることが予想されたので、データの組み合わせフラグを作成しました。用意したデータの種類は、全部で6種類となるので、その組み合わせは全部で63通りとなります。63通りの特徴量を作成し、その特徴量ごとに予測モデルを作成して予測精度を評価します。組み合わせ表を作成するプログラムは前回の検証を参照してください。
<組み合わせ表の一部>
セルが「1」となっている場合、そのデータを特徴量に追加します。
|
円ドル為替 |
ダウ平均 |
NASDAQ |
日経平均 |
自己回帰 |
移動平均 |
|
1 |
1 |
1 |
1 |
1 |
1 |
|
1 |
1 |
1 |
1 |
1 |
0 |
|
1 |
1 |
1 |
1 |
0 |
1 |
|
1 |
1 |
1 |
1 |
0 |
0 |
|
1 |
1 |
1 |
0 |
1 |
1 |
|
1 |
1 |
1 |
0 |
1 |
0 |
|
1 |
1 |
1 |
0 |
0 |
1 |
|
1 |
1 |
1 |
0 |
0 |
0 |
|
1 |
1 |
0 |
1 |
1 |
1 |
|
1 |
1 |
0 |
1 |
1 |
0 |
過去データを特徴量として使用する方法
shift関数を用いて、データをシフトします。
5日シフト、10日シフトするイメージは下記の通りです。
<スライドのイメージ>

シフトする区間は36~600としています。
予測する期間を2020/11/11~2020/12/30としており、その期間の株取引回数は36回です。シフト数を36未満に設定すると、取得していない未来データを用いることになってしまいます。
<シフト数を14に設定した場合のイメージ>

作成する特徴量の総数
特徴量に過去データを含めるので、特徴量の総数は下記となります。
特徴量の総数:35,595=データ組み合わせ63通り×シフト区間36~600(シフト数は565)
評価の高いデータ・シフトの組み合わせを探す
コードの動作概要、作成したコード、実行した結果のサンプルを下記に記載しました。
コードの動作概要
コードの動作概要と該当する行を下記に記載しました。
データの読み込み、特徴量の作成、予測モデルの作成、予測モデルの評価などは、関数として定義しています。
| No | 概要 | 行 |
| 1 | ライブラリの読み込み | 1~26行 |
| 2 | mainの開始位置 | 28行 |
| 3 | 予測対象の株価データ、外部データを読み込んで辞書に登録する | 31~40行 |
| 4 | 予測したデータの評価結果を保存するデータフレームを作成する | 45~48行 |
| 5 | 株価を予測して評価する処理の開始位置 | 51行 |
| 6 | 外部データの組み合わせ用フラグを読み込んで辞書に登録する | 54~66行 |
| 7 | 評価結果を保存するデータフレーム、フラグに応じた特徴量を作成する | 69~72行 |
| 8 | シフトの開始位置と終了位置を設定する | 76~77行 |
| 9 | 予測と評価のループ開始位置 | 80行 |
| 10 | 特徴量をシフトした後、その特徴量を訓練データと検証データに分割する | 84~87行 |
| 11 | 予測モデルを作成し、株価を予測する | 90~93行 |
| 12 | 予測した結果を評価して保存する | 96~99行 |
| 13 | 評価が最も高かったr2、rmse、シフトした値を保存する | 102~105行 |
| 14 | 評価結果をCSVファイルに保存する | 108行 |
| 15 | 予測と評価の結果をグラフで表示する | 111行 |
| 16 | mainで呼び出している関数を定義している | 115~335行 |
作成したコード
掲載したコードは、111行目をコメントアウトしています。コメントアウトを外すと、予測結果と評価を実行したあと、毎回グラフを表示することになります。
# データフレームを扱うライブラリを読み込む
import pandas as pd
# fbprophetのライブラリを読み込む
from fbprophet import Prophet
# R2を計算するためのライブラリを読み込む
from sklearn.metrics import r2_score
# RMSEを計算するためのライブラリを読み込む
from sklearn.metrics import mean_squared_error
# numpyのライブラリを読み込む
import numpy as np
# プログレスバーを表示するためのライブラリを読み込む
from tqdm import tqdm
# グラフ表示関連のライブラリを読み込む
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import japanize_matplotlib
from matplotlib.dates import date2num
# 日付を扱うためのライブラリを読み込む
from datetime import datetime
# main
def main():
# 予測に必要な全データを読み込む
JPYUSD, DJI, IXIC, N225, shift, MA, df_base, merge_flag = load_data()
# データの辞書を設定する
dict_data = {'JPYUSD': JPYUSD,
'DJI': DJI,
'IXIC': IXIC,
'N225': N225,
'shift': shift,
'MA': MA,
'df_base': df_base}
# 特徴量に応じた評価結果を保存するデータフレームを用意する
# 自己回帰データを作成するためにshift関数でシフトした値を保存するカラムを追加する
# r2、rmseの計算結果を保存するカラムを追加する
df_result = merge_flag.copy()
df_result['shift'] = 0
df_result['r2'] = 0
df_result['rmse'] = 0
# 株価を予測して、結果を評価する
for i in tqdm(range(len(merge_flag))):
# merge_flagから特徴量に追加するデータを選択し、特徴量を作成する
# 各データのフラグを用意し、追加する場合は1,追加しない場合は0を代入する
JPYUSD_f = merge_flag.iloc[i, 0]
DJI_f = merge_flag.iloc[i, 1]
IXIC_f = merge_flag.iloc[i, 2]
N225_f = merge_flag.iloc[i, 3]
shift_f = merge_flag.iloc[i, 4]
MA_f = merge_flag.iloc[i, 5]
dict_flag = {'JPYUSD': JPYUSD_f,
'DJI': DJI_f,
'IXIC': IXIC_f,
'N225': N225_f,
'shift': shift_f,
'MA': MA_f}
# r2とrmseの計算結果を保存するデータフレームを作成する
df_result_score = pd.DataFrame(columns=['shift', 'r2', 'rmse'])
# 特徴量を作成する
df_feature_base = make_feature(dict_data, dict_flag)
# シフトする値を設定する
# 2020/11/11~2020/12/31までを予測するので、shift_startは36以上を設定する
shift_start = 36
shift_end = 100
# シフトを+1づつ行う
for s in range(shift_start, shift_end+1):
print('merge_flag:', i)
print('shift:', s)
# 特徴量の説明変数をシフトする
df_feature = shift_data(df_feature_base, dict_data['df_base'], s)
# 訓練データと検証データを作成する
x_train, x_test, dates_test = make_trainData_testData(df_feature, s)
# モデルを定義して学習する
model = make_model(x_train, dict_flag)
# 株価を予測する
forecast = model_predict(df_feature, model)
# r2,rmseの計算を行う
r2, rmse, ypred, ytest = score(forecast, x_test, s)
# R2とRMSEの計算結果を保存する
df_result_score = df_result_score.append({'shift': s, 'r2': r2, 'rmse': rmse}, ignore_index=True)
# r2の計算結果が最も高かったshift,rmseの計算結果を保存する
r2_max = df_result_score['r2'].idxmax()
df_result.iloc[i, -3] = df_result_score.iloc[r2_max, 0]
df_result.iloc[i, -2] = df_result_score.iloc[r2_max, 1]
df_result.iloc[i, -1] = df_result_score.iloc[r2_max, 2]
# 結果をCSVに保存する
df_result.to_csv(f'./result_logistic/shift_{shift_start}_{shift_end}_result.csv')
# グラフを描画する
# draw_graph(model, forecast, dates_test, r2, rmse, ypred, ytest)
# データを読み込む関数
def load_data():
# 予測したい株価(toyota7203)を読み込む
df_load = pd.read_csv('./stock_info/7203.csv', index_col=0, parse_dates=True)
# 読み込んだ株価を日付で昇順に変換する
df_load = df_load[::-1]
# 予測対象の日付と終値を保存するdf_baseを新規に作成する
df_base = pd.DataFrame()
# df_baseにdf_loadから日付と終値を追加する
df_base['Date'] = df_load.index.values
df_base['Close'] = df_load['Close'].values
# 円ドル為替の時系列データを読み込む
JPYUSD = pd.read_csv('./stock_info/JPY_USD.csv', index_col=0, parse_dates=True)
# ダウ平均(DJI)の時系列データを読み込む
DJI = pd.read_csv('./stock_info/DJI.csv', index_col=0, parse_dates=True)
# NASDAQ(IXIC)の時系列データを読み込む
IXIC = pd.read_csv('./stock_info/IXIC.csv', index_col=0, parse_dates=True)
# 日経平均(N225)の時系列データを読み込む
N225 = pd.read_csv('./stock_info/N225.csv', index_col=0, parse_dates=True)
# 自己回帰データ用のデータフレームを用意する
shift = pd.DataFrame(index=df_load.index, columns=[])
shift['Close'] = df_load.loc[:, 'Close']
# 終値の移動平均を追加したデータフレームを用意する
# 7回の取引の移動平均を算出する
MA = pd.DataFrame(index=df_load.index, columns=[])
MA['Close'] = df_load.loc[:, 'Close']
window = 7
min_periods = 1
MA = MA.rolling(window=window, min_periods=min_periods).mean()
# 特徴量に含めるかを判定するフラグを読み込む
merge_flag = pd.read_csv('./stock_info/merge_flag.csv')
return JPYUSD, DJI, IXIC, N225, shift, MA, df_base, merge_flag
# 特徴量を作成する関数
def make_feature(dict_data, dict_flag):
# 特徴量を作成する
# dict_dataのdf_base、予測したい株価を読み込む
df_make_feature = dict_data['df_base'].copy()
# フラグに応じて、JPYUSD,DJI,IXIC,N225,Close_shift,Close_MAを説明変数として特徴量に追加する
for i in range(len(dict_flag)):
if list(dict_flag.values())[i] == 1:
df_make_feature = pd.merge(df_make_feature,
list(dict_data.values())[i]['Close'],
how='left',
on='Date',
suffixes=['', '_'+list(dict_flag.keys())[i]])
# 欠損しているセルを後ろの値で補完する
df_make_feature = df_make_feature.fillna(method='bfill')
return df_make_feature
# 説明変数をシフトして特徴量に追加する関数
def shift_data(df_feature, df_base, shift):
# 説明変数だけを抽出する
df_tmp1 = df_feature.drop(['Date', 'Close'], axis=1)
# 説明変数をシフトする
df_shift = df_tmp1.shift(shift)
# シフトした説明変数をdf_baseに結合する
df_feature = pd.concat([df_base, df_shift], axis=1)
# シフトしたので、開始日を変更する
start_day = df_feature.iloc[shift, 0]
# 開始日用のindexを作成する
start_index = df_feature['Date'] >= start_day
# 開始日を移動したデータを作成する
df_feature = df_feature[start_index]
return df_feature
# 訓練データと検証データを作成する関数
def make_trainData_testData(df_feature, shift):
# fbprophetで扱えるカラム名に変更する
df_feature = df_feature.rename(columns={'Date': 'ds', 'Close': 'y'})
# 訓練データと検証データを分割する
# 訓練データ:2018-02-27 ~ 2020-11-09
# 検証データ:2020-11-10 ~ 2020-12-30
# 分割日split_dayを設定する
split_day = pd.to_datetime('2020-11-10')
end_day = pd.to_datetime('2020-12-30')
# 分割日を起点にtrueとfalseを割り当てる
# train_indexは691行目までTrueで、692~727行目までFalseとなり、
# test_indexは691行目までFalseで、692~727行目までTrueとなる
train_index = df_feature['ds'] < split_day test_index = df_feature['ds'] >= split_day
# 訓練データと検証データを作成する
x_train = df_feature[train_index]
x_test = df_feature[test_index]
# 予測データと検証データをグラフ表示する際に使用する日付を設定する
# 設定する日付は2020-11-10 ~ 2020-12-30となる
dates_test = df_feature['ds'][test_index]
return x_train, x_test, dates_test
# モデルを定義して学習する関数
def make_model(x_train, dict_flag):
# モデルを定義する
model = Prophet(growth='logistic',
yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=False,
seasonality_mode='multiplicative')
# フラグに応じて、説明変数をモデルに組み込む
for i in range(len(dict_flag)):
if list(dict_flag.values())[i] == 1:
model.add_regressor('Close_'+list(dict_flag.keys())[i])
# cap(上限値)、floor(下限値)を設定する
x_train['cap'] = 8500
x_train['floor'] = 0
# モデルを学習する
model.fit(x_train)
return model
# 予測する関数
def model_predict(df_feature, model):
# 予測用データを作成する
df_predicct = df_feature.drop('Close', axis=1)
df_predicct = df_predicct.rename(columns={'Date': 'ds'})
# cap(上限値)、floor(下限値)を設定する
df_predicct['cap'] = 8500
df_predicct['floor'] = 0
# 予測する
forecast = model.predict(df_predicct)
return forecast
# r2,rmseを計算する関数
def score(forecast, x_test, shift):
# forecastから予測部分yhatのみ抽出する
# 2020-11-10から2020-12-30の期間で株取引が行われた日数は36日となる
ypred = forecast[-36:][['yhat']].values
# forecastから予測部分yhatのみ抽出する
# 2020-11-10から2020-12-30の期間で株取引が行われた日数は36日となる
ypred = forecast[-36:][['yhat']].values
# ytest:予測期間中の正解データを抽出する
ytest = x_test['y'].values
# R2値,RMSEを計算する
r2 = r2_score(ytest, ypred)
rmse = np.sqrt(mean_squared_error(ytest, ypred))
return r2, rmse, ypred, ytest
# グラフを描画する関数
def draw_graph(model, forecast, dates_test, r2, rmse, ypred, ytest):
# 要素ごとのグラフを描画する
# トレンド、週周期、年周期を描画する
fig = model.plot_components(forecast)
# 訓練データ・検証データ全体のグラフ化
fig, ax = plt.subplots(figsize=(10, 6))
# 予測結果のグラフ表示(prophetの関数)
model.plot(forecast, ax=ax)
# タイトル設定など
ax.set_title('終値の予測')
ax.set_xlabel('日付')
ax.set_ylabel('終値')
# 時系列グラフを描画する
fig, ax = plt.subplots(figsize=(8, 4))
# グラフを描画する
ax.plot(dates_test, ytest, label='正解データ', c='k')
ax.plot(dates_test, ypred, label='予測結果', c='r')
# 日付目盛間隔を表示する
# 木曜日ごとに日付を表示する
weeks = mdates.WeekdayLocator(byweekday=mdates.TH)
ax.xaxis.set_major_locator(weeks)
# 日付表記を90度回転する
ax.tick_params(axis='x', rotation=90)
# 方眼表示、凡例、タイトルを設定する
ax.grid()
ax.legend()
ax.set_title('終値の予測')
# x座標:2020年11月19日、y座標:7800にscore_r2とscore_rmseを表示する
xdata = date2num(datetime(2020, 11, 19))
ax.text(xdata, 7800, f'socre_R2:{r2:.4f}\nscore_RMSE:{rmse:.4f}', size=15)
# ax.text(xdata, 6600, f'socre_RMSE:{score_rmse:.4f}', size=15)
# 画面出力
plt.show()
if __name__ == "__main__":
main()実行した結果
コードを実行する前に、コードと同じ場所に「result_logistic」フォルダを作成しておきます。
データの組み合わせごとに、76、77行で指定したシフト区間で最も評価の高かったシフト値とR2とRMSE値をCSVファイルに保存します。CSVファイルはコードを配置したresult_logisticフォルダに保存されます。
<開始位置:36~終了位置:100の実行結果の一部>
A列が組み合わせの番号です。
2行目は全てのフラグが「1」になっているので、外部データと自己回帰データが全て含まれています。
H列がR2が最も高かったシフト値となります。
2行目のH列は「36」なので、フラグ番号0において最も高かったシフト値は「36」となります。
5行目のH列は「83」なので、フラグ番号3において最も高かったシフト値は「83」となります。

<開始位置:351~終了位置:400の実行結果の一部>

6行目のフラグ番号4でシフト385で、R2値が最も高い値となりました。
データの組み合わせとシフト値を指定する方法
評価が最も高かったフラグ番号4とシフト値385で予測モデルを作成する方法は、下記のコードを書き換える必要があります。
51行目でフラグ番号を指定します。
rangeの範囲を4に設定します。
変更前
for i in tqdm(range(len(merge_flag))):
変更後
for i in tqdm(range(4, 5)):シフト値は76,77行目を同じ値に設定します。
shift_start = 385
shift_end = 385検証結果の眺めて気づいたこと
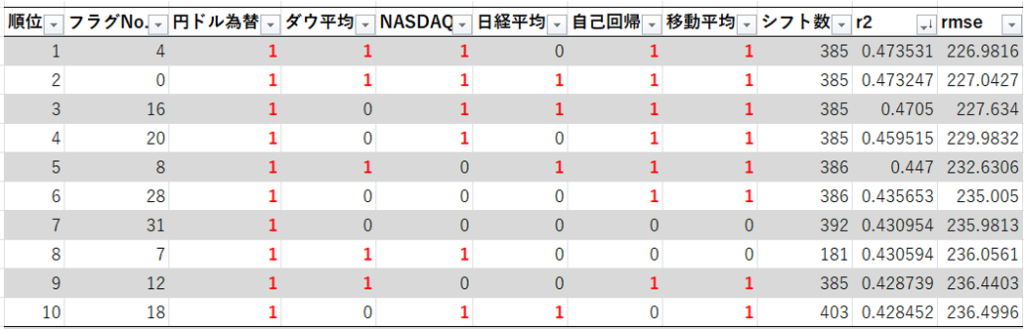
R2の評価値の上位10をまとめてみました。
R2の評価値の上位10には、円ドル為替の外部データが必ず含まれています。
順位7では、円ドル為替のデータのみでした。
トヨタは輸出が多い企業なので、円ドル為替の外部データの影響が大きいのでしょうか。日経平均のデータは半分も含まれていないので、日本経済にはあまり影響を受けていないのですかね。
色々な企業の株価で検証してみたいのですが、私の実行環境だとかなりの時間を要するので、手軽に検証できない。。。
次回試したいこと
fbprophetには、どのデータが予測結果に影響を与えているのかを確認することができません。
データの影響度を確認できるXGBoost、LightGBMあたりで株価予測を検証してみます。


コメント