はじめに
前回は、自己回帰データのみを使用して予測モデルを作成しました。
今回は複数の外部データを利用して予測モデルの精度向上を試してみました。
結果は、予測精度の低いモデルしか作成できませんでした。
予測検証の概要は以下のとおりです。
| 予測する株価 | 7203(トヨタ)の終値 |
| 予測に使用する訓練データの期間 | 2016/1/4~2021/12/3 |
| 予測モデルを評価するデータの期間 | 2021/12/4~2022/1/20 |
| 予測に使用する特徴量 | 為替、日経平均、ダウ平均、NASDAQ、開始値、終値、低値、高値、取引高 ※太字が前回から追加した外部データ |
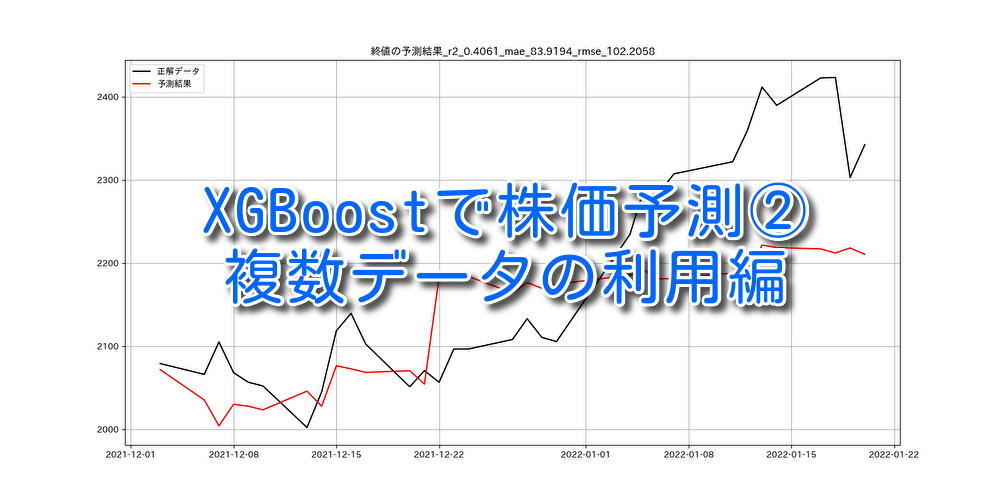
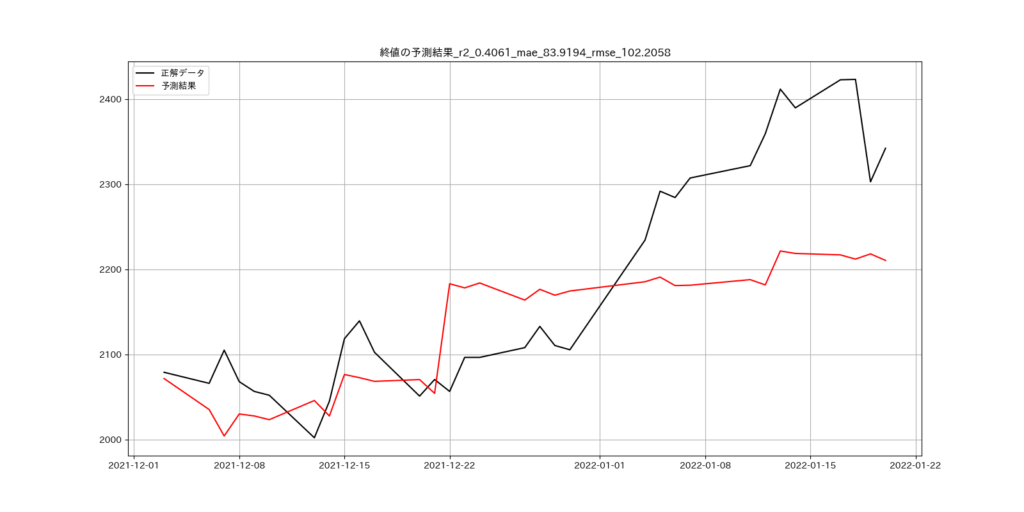
予測検証で最も評価が高かった結果
| 評価項目 | 評価値 |
| R2 | 0.406 |
| MAE | 83.919 |
| RMSE | 102.205 |
予測モデル作成で使用した外部データの取得方法
為替、日経平均、ダウ平均、NASDAQは以前に取得した方法でCSVで保存しておきます。
プログラムの概要
プログラムの概要と該当する行を下記に記載しました。
移動平均の算出、ラグ特徴の作成、訓練データと検証データの作成、学習/予測/評価の実施は、関数として定義しています。
| No. | 概要 | 該当行 |
| ライブラリの読み込む | 1~42 | |
| mainの開始位置 | 43 | |
| 予測の評価結果を保存するフォルダを作成する | 44~52 | |
| 予測の評価結果を保存するデータフレームを用意する | 54~55 | |
| データの読み込む | 60 | |
| 特徴量の作成 | 62~77 | |
| 特徴量を訓練データと検証データに分割する | 80 | |
| 学習、予測、評価を行う | 83 | |
| 評価結果をデータフレームに保存する | 86~87 | |
| 評価結果をCSVに保存する | 90~91 | |
| モデルを学習する際に使用した列を記録する | 93~96 | |
| 関数定義 | 99~235 |
作成したコード
掲載したコードの215行目と235行目をコメントアウトしています。コメントアウトを外すと、重要度分析と終値の予測結果のグラフを表示することができます。
# グラフを描画するライブラリを読み込む
import matplotlib.pyplot as plt
import japanize_matplotlib
from matplotlib.dates import date2num
# データフレームを扱うライブラリを読み込む
import pandas as pd
import pandas_datareader as web
# xgboostのライブラリを読み込む
from xgboost import XGBRegressor
import xgboost as xgb
# R2を計算するためのライブラリを読み込む
from sklearn.metrics import r2_score
# MAEを計算するためのライブラリを読み込む
from sklearn.metrics import mean_absolute_error
# RMSEを計算するためのライブラリを読み込む
from sklearn.metrics import mean_squared_error
# 標準化するためのライブラリを読み込む
from sklearn.preprocessing import StandardScaler
# numpyを扱うためのライブラリを読み込む
import numpy as np
# 日付を扱うためのライブラリを読み込む
from datetime import datetime
# プログレスバーを表示するためのライブラリを読み込む
from tqdm import tqdm
# フォルダを作成するためのライブラリを読み込む
import os
# 警告メッセージを無効にする
import warnings
warnings.simplefilter('ignore')
def main():
# 予測の評価結果を保存するフォルダを設定する
# 現在の時刻を取得する
now = datetime.now()
# ファイル名、フォルダ名に時刻を設定するために形式を整える
f_time = now.strftime('%Y%m%d-%H%M%S')
# 予測結果を保存するフォルダを作成する
os.mkdir('./result/{}'.format(f_time))
# 予測の評価結果を保存するデータフレームを用意する
df_result = pd.DataFrame()
# モデル作成時に使用するデータの開始位置を0から900まで100刻みでスライドする
for d in tqdm(range(0, 1000, 100)):
# データの読み込み
df_dataset, start_day = load_data(d)
# 年、月、日、曜日の列を追加する
df_dataset['年'] = df_dataset.index.year
df_dataset['月'] = df_dataset.index.month
df_dataset['日'] = df_dataset.index.day
df_dataset['曜日'] = df_dataset.index.weekday
for window in tqdm(range(3, 30)):
# 移動平均を追加したデータセットを用意する
df_ma_dataset = move_average_dataset(window, window, df_dataset)
# lag特徴を30~199で設定し、特徴量を作成する
for lag in tqdm(range(30, 200)):
# ラグ特徴を追加する
df_lag_dataset = df_ma_dataset.copy()
df_lag_dataset = lag_dateset(lag, df_lag_dataset)
# 訓練データと検証データに分割する
x_train, y_train, x_test, y_test, dates_test = train_valid_split(df_lag_dataset)
# 学習、予測、評価を行う
r2, mae, rmse = fit_predict_score(x_train, y_train, x_test, y_test, dates_test)
# 評価をデータフレームに保存する
df_tmp = pd.DataFrame({'start_day': [start_day], 'window': [window], 'lag': [lag], 'r2': [r2], 'mae': [mae], 'rmse': [rmse]})
df_result = df_result.append(df_tmp)
# 評価をCSVファイルに保存する
df_result = df_result.sort_values('r2', ascending=False)
df_result.to_csv('./result/' + f'{f_time}/' + 'predict_7203.csv', sep=',')
# モデルを学習する際に使用した列を記録しておく
with open('./result/' + f'{f_time}/' + 'columns.txt', 'w') as f:
for column in list(x_train.columns):
f.write(f'{column}\n')
def load_data(days):
# 読み込むデータの保存先のパスを指定する
save_path = './外部データ/'
# 証券コードを指定する
# 日本株の場合は、証券コードの最後に'.JP'を付ける
# トヨタ7203の場合は、'7203.JP'となる
stock_code = '7203.JP'
# 予測したい株価(toyota7203)を読み込む
df_stock = pd.read_csv(save_path + stock_code + '.csv', index_col=0, parse_dates=True)
# 株価情報と追加情報を結合するためのデータフレームを用意する
df_merge = df_stock.copy()
from datetime import timedelta
# モデル作成で使用するデータ開始の初期値を設定する
mday = datetime(2016, 1, 1)
# モデル作成で使用するデータの開始位置を設定する
mday = mday + timedelta(days=days)
# データの開始位置
mday_index = df_merge.index >= mday
# データを作成する
df_merge = df_merge[mday_index]
# 為替、日経平均、ナスダック、ダウの情報を読み込む
for code in ['JPY=X', '^N225', '^IXIC', '^DJI']:
df_tmp = pd.read_csv(save_path + code + '.csv', index_col=0, parse_dates=True)
df_merge = pd.merge(df_merge, df_tmp, left_index=True, right_index=True, suffixes=['', '_' + code])
return df_merge, mday
def move_average_dataset(window, min_periods, df_d):
# 各列の移動平均をデータに追加する
df_d['Open_ma'] = df_d['Open'].rolling(window=window, min_periods=min_periods).mean()
df_d['High_ma'] = df_d['High'].rolling(window=window, min_periods=min_periods).mean()
df_d['Low_ma'] = df_d['Low'].rolling(window=window, min_periods=min_periods).mean()
df_d['Close_ma'] = df_d['Close'].rolling(window=window, min_periods=min_periods).mean()
df_d['Volume_ma'] = df_d['Volume'].rolling(window=window, min_periods=min_periods).mean()
# 移動平均を計算できない行を省いてデータセットに代入する
df_d = df_d[int(window - 1):]
return df_d
def lag_dateset(shift, df_d):
# シフト関数でデータをシフトする
df_d_shift = df_d.shift(shift)
# シフトしたデータを結合する
df_d = pd.merge(df_d, df_d_shift, right_index=True, left_index=True, suffixes=('', '_shift'))
# シフトしてnanになった分を除外する
df_d = df_d[shift:]
# リークさせないために、不要なOpen、High、Low、Volumeなどを削除したデータセットを作成する
drop_list = ['Open', 'High', 'Low', 'Volume',
'Open_ma', 'High_ma', 'Low_ma', 'Close_ma', 'Volume_ma',
'Open_JPY=X', 'High_JPY=X', 'Low_JPY=X', 'Close_JPY=X', 'Volume_JPY=X', 'Adj Close',
'Open_^N225', 'High_^N225', 'Low_^N225', 'Close_^N225', 'Volume_^N225', 'Adj Close_^N225',
'Open_^IXIC', 'High_^IXIC', 'Low_^IXIC', 'Close_^IXIC', 'Volume_^IXIC', 'Adj Close_^IXIC',
'Open_^DJI', 'High_^DJI', 'Low_^DJI', 'Close_^DJI', 'Volume_^DJI', 'Adj Close_^DJI']
# 不要な列を削除する
df_d = df_d.drop(drop_list, axis=1)
return df_d
def train_valid_split(df_d):
# df_datesetを説明変数:xと目的変数:yに分割する
x = df_d.drop('Close', axis=1)
y = df_d['Close'].values
# 訓練データと検証データを分割するmdayを設定する
mday = pd.to_datetime('2021-12-03')
# 訓練データ用indexと検証データ用indexを作る
train_index = df_d.index < mday test_index = df_d.index >= mday
# 訓練データを作成する
x_train = x[train_index]
y_train = y[train_index]
# 検証データを作成する
x_test = x[test_index]
y_test = y[test_index]
# グラフ表示用の日付を抽出する
dates_test = x_test.index.values
return x_train, y_train, x_test, y_test, dates_test
def fit_predict_score(x_tr, y_tr, x_te, y_te, dates_test):
# アルゴリズムを設定する
alg = XGBRegressor(objective='reg:squarederror', random_state=123)
# 学習する
alg.fit(x_tr, y_tr)
# 予測する
y_pred = alg.predict(x_te)
# 評価する
r2 = r2_score(y_te, y_pred)
mae = mean_absolute_error(y_te, y_pred)
rmse = np.sqrt(mean_squared_error(y_te, y_pred))
'''
# 説明変数ごとの重要度を確認する
fig, ax = plt.subplots(figsize=(16, 8))
xgb.plot_importance(alg, ax=ax, height=0.8, importance_type='gain', show_values=False,
title=f'重要度分析_r2_{r2:.4f}_mae_{mae:.4f}_rmse_{rmse:.4f}')
plt.savefig(f'重要度分析_r2_{r2:.4f}_mae_{mae:.4f}_rmse_{rmse:.4f}.png')
plt.show()
# 実データと予測データを比較する
fig, ax = plt.subplots(figsize=(16, 8))
ax.plot(dates_test, y_te, label='正解データ', c='k')
ax.plot(dates_test, y_pred, label='予測結果', c='r')
ax.grid()
ax.legend()
ax.set_title(f'終値の予測結果_r2_{r2:.4f}_mae_{mae:.4f}_rmse_{rmse:.4f}')
plt.savefig(f'終値の予測結果_r2_{r2:.4f}_mae_{mae:.4f}_rmse_{rmse:.4f}.png')
plt.show()
return r2, mae, rmse
'''
if __name__ == "__main__":
main()コードの補足
使用データの期間スライドの説明
使用するデータの期間は2016/1/4から2022/1/20です。使用するデータ量によって予測結果の評価が変わるので、使用するデータ開始位置をスライドさせて予測モデルを作成してみました。
for d in tqdm(range(0, 1000, 100)):
58行目を上記のように指定した場合、予測モデルを作成するときのデータ開始位置は下記のようになります。
- 2016/1/4
- 2016/4/13(=2016/1/4+100日)
- 2016/7/22(=2016/4/13+100日)
- 2016/10/30(=2016/7/22+100日)
- 2017/2/7(=2016/10/30+100日)
- 2017/5/18(=2017/2/7+100日)
- 2017/8/26(=2017/5/18+100日)
- 2017/12/4(=2017/8/26+100日)
- 2018/3/13(=2017/12/4+100日)
- 2018/6/22(=2018/3/13+100日)
移動平均、lag特徴の説明
69~71行目に移動平均を設定する関数、move_average_datasetを用意しました。
rollingを使用して指定された期間の移動平均を設定します。
74~77行目にlag特徴を設定する関数、lag_datasetを用意しました。
shiftを使用して指定された期間でデータをシフトし、元のデータに結合しています。
移動平均とlag特徴については、前回作成したコードを流用しています。
プログラムの実行結果
予測モデルを作成し、予測評価を行います。その結果を2つのファイルに保存します。
1.columns.txt
モデルを学習するときに使用した特徴量を記録したテキストを作成します。
2.predict_7203.csv
設定したstart_day(データ開始位置)、window(移動平均のサイズ)、lag(ラグ特徴のサイズ)、r2、mae、rmseのカラムを持ったCSVファイルを作成します。CSVを保存する前に、r2で降順ソートを行います。
215行目と235行目のコメントアウトを外すと、終値の予測結果と重要度分析のグラフを表示して、そのグラフ画像を保存します。
終値の実データと予測データの比較結果
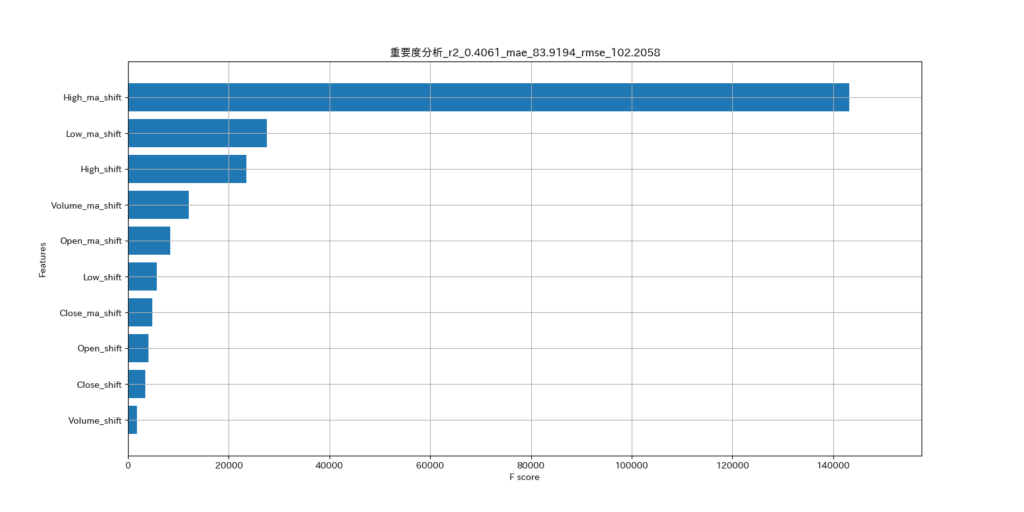
 重要度分析のグラフ
重要度分析のグラフ
予測結果について
特徴量を増やすことで、予測の精度を向上できると考えましたが、向上させることはできませんでした。為替、日経平均、ダウ平均、NASDAQのデータを使用することで予測精度の向上を試みましたが、向上しませんでした。むしろ、それらの外部データがあることで予測精度は低下しました。
「AIだからとりあえずデータを放り込んでみよう」の考えだとうまくいかない、ことを学びました。
次回、試したいこと
ガソリンの小売価格、自動車の素材価格、自動車の部品価格、自動車メーカー同士の相関関係、などを外部データとして用いることで予測精度を向上させることができないか、検証してみます。
外部データは、政府統計からの取得を試みてみます。
政府統計の総合窓口 (e-stat.go.jp)


コメント