はじめに
kaggleなどでよく使用されている機械学習アルゴリズムのXGBoostで株価を予測してみました。
予測検証の概要は下記の通りです。
- 予測する株価:7203(トヨタ)の終値
- 予測に使用する訓練データの期間:2018/1/4~2020/11/10
- 予測モデルを評価するデータ期間:2020/11/11~2020/12/30
- 予測に使用する特徴量:開始値、終値、高値、低値、取引高のラグ特徴と移動平均
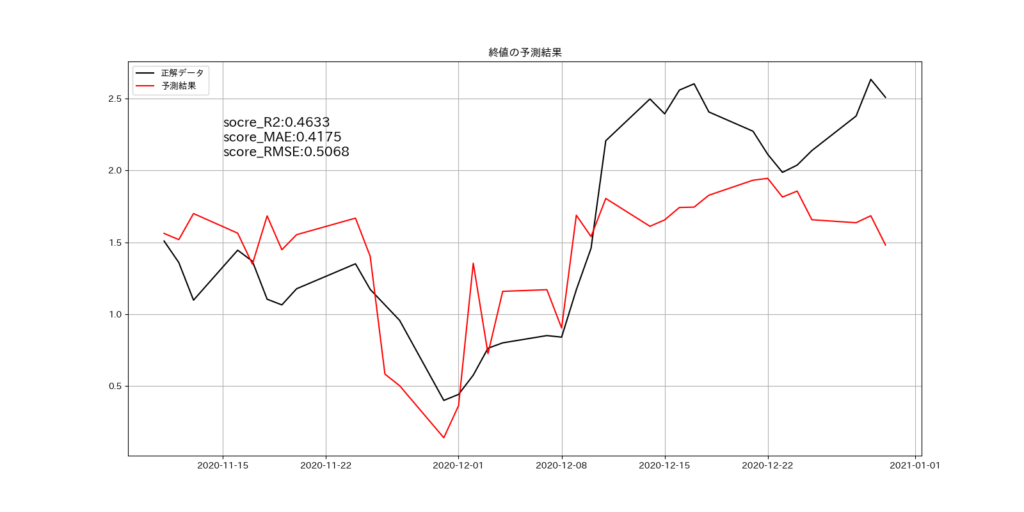
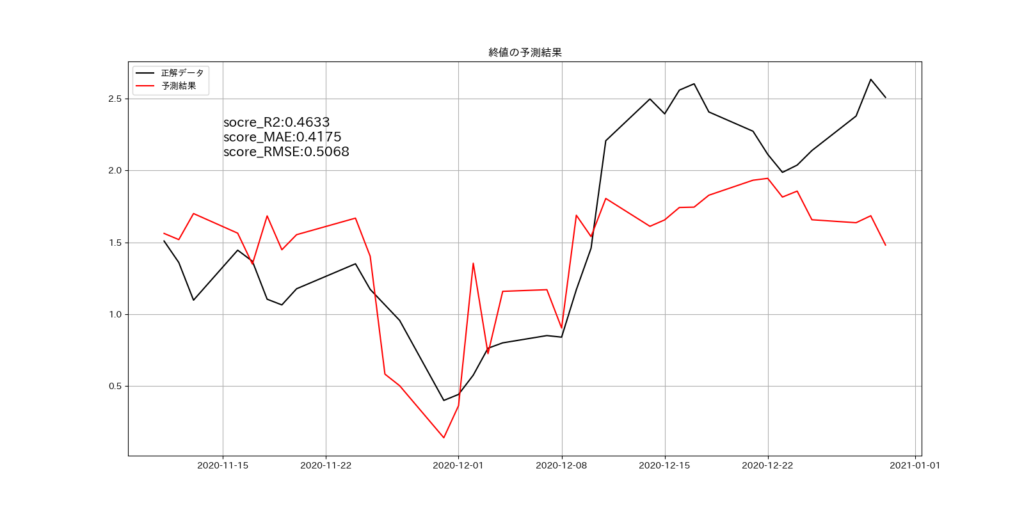
ラグ特徴と移動平均を調整することで、予測モデルの性能目安となる決定係数R2の値は「0.4633」とすることができました。XGBoostのハイパーパラメータを調整は実施していません。
| 評価項目 | 評価値 |
| R2 | 0.4633 |
| MAE | 0.4175 |
| RMSE | 0.5068 |
正解データと予測結果を比較したグラフは下記の通りです。
特徴量の説明
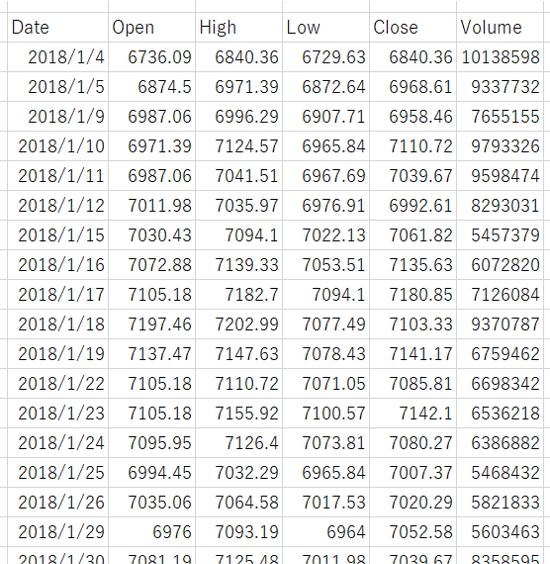
株価のデータ取得は、「Pythonで株の情報を取得したい」の方法で取得します。取得したデータをCSV形式で保存しておきます。CSVファイルを開くと、Date、Open、High、Low、Close、Volumeの5つの情報を日ごとに確認することができます。
予測モデルは回帰モデルで作成する
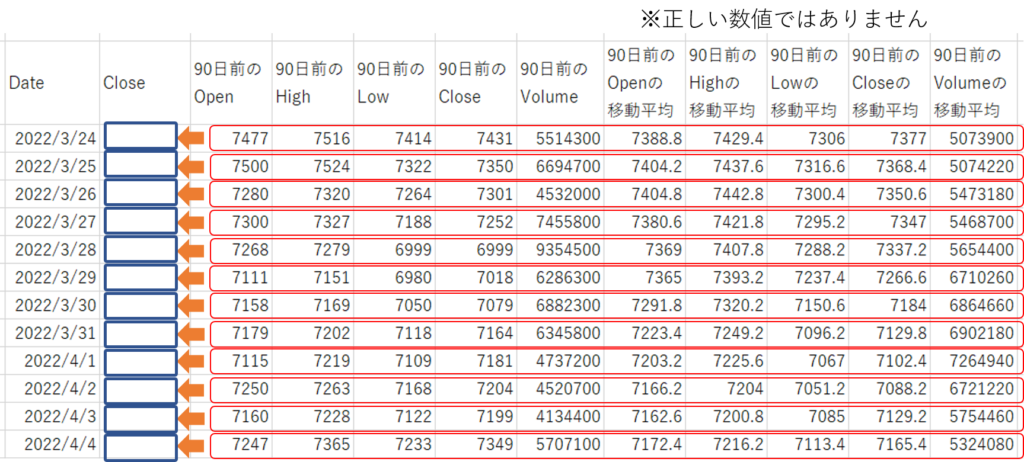
予測モデルは回帰モデルで作成します。使用する特徴量は、自己回帰データとなる「X日前」のOpen、High、Low、Close、Volumeと、その移動平均値です。
予測モデルの予測イメージ図を下記に記載しました。
赤枠の情報を使って、青枠の情報を予測します。
プログラムの概要
プログラムの概要と該当する行を下記に記載しました。
移動平均の算出、ラグ特徴の作成、訓練データと検証データの作成、学習/予測/評価の実施は、関数として定義しています。
| No. | 概要 | 該当行 |
| 1 | ライブラリの読み込み | 1~32 |
| 2 | mainの開始位置 | 36 |
| 3 | 株価データを読み込む | 37~41 |
| 4 | 移動平均の範囲を指定する | 46 |
| 5 | ラグ特徴の範囲を指定する | 50 |
| 6 | 株価データにラグ特徴を追加する | 52~53 |
| 7 | 訓練データと検証データを分割する | 56 |
| 8 | 学習、予測、評価を行う | 59 |
| 9 | 評価結果をCSVファイルに保存する | 62~66 |
| 10 | 移動平均を算出する関数 | 69~80 |
| 11 | ラグ特徴を算出する関数 | 83~96 |
| 12 | 訓練データと検証データを作成する関数 | 99~127 |
| 13 | 学習、予測、評価を行う関数 | 130~169 |
作成したコード
掲載したコードの145行目と167行目をコメントアウトしています。コメントアウトを外すと、重要度分析と終値の予測結果のグラフを表示することができます。
# グラフを描画するライブラリを読み込む
import matplotlib.pyplot as plt
import japanize_matplotlib
from matplotlib.dates import date2num
# データフレームを扱うライブラリを読み込む
import pandas as pd
# xgboostのライブラリを読み込む
from xgboost import XGBRegressor
import xgboost as xgb
# R2を計算するためのライブラリを読み込む
from sklearn.metrics import r2_score
# MAEを計算するためのライブラリを読み込む
from sklearn.metrics import mean_absolute_error
# RMSEを計算するためのライブラリを読み込む
from sklearn.metrics import mean_squared_error
# 標準化するためのライブラリを読み込む
from sklearn.preprocessing import StandardScaler
# numpyを扱うためのライブラリを読み込む
import numpy as np
# 日付を扱うためのライブラリを読み込む
from datetime import datetime
# プログレスバーを表示するためのライブラリを読み込む
from tqdm import tqdm
# main
def main():
# 予測したい株価(toyota7203)を読み込む
df_stockinfo = pd.read_csv('./stock_info/7203.csv', index_col=0, parse_dates=True)
# 読み込んだ株価を日付で昇順に変換する
df_stockinfo = df_stockinfo[::-1]
# 予測の評価結果を保存するデータフレームを用意する
df_result = pd.DataFrame()
for w in tqdm(range(5, 20)):
# 移動平均を追加したデータセットを用意する
df_ma_dateset = move_average_dateset(w, w, df_stockinfo)
for l in tqdm(range(35, 36)):
# ラグ特徴を追加する
df_lag_dateset = df_ma_dateset.copy()
df_lag_dateset = lag_dateset(l, df_lag_dateset)
# 訓練データと検証データに分割する
x_train, y_train, x_test, y_test, dates_test = train_valid_split(df_lag_dateset)
# 学習、予測、評価を行う
r2, mae, rmse = fit_predict_score(x_train, y_train, x_test, y_test, dates_test)
# 評価をデータフレームに保存する
df_tmp = pd.DataFrame({'window': [w], 'lag': [l], 'r2': [r2], 'mae': [mae], 'rmse': [rmse]})
df_result = df_result.append(df_tmp)
# 評価をCSVファイルに保存する
df_result.to_csv('predict_7203.csv', sep=',')
def move_average_dateset(window, min_periods, df_dateset):
# 各列の移動平均をデータに追加する
df_dateset['Open_ma'] = df_dateset['Open'].rolling(window=window, min_periods=min_periods).mean()
df_dateset['High_ma'] = df_dateset['High'].rolling(window=window, min_periods=min_periods).mean()
df_dateset['Low_ma'] = df_dateset['Low'].rolling(window=window, min_periods=min_periods).mean()
df_dateset['Close_ma'] = df_dateset['Close'].rolling(window=window, min_periods=min_periods).mean()
df_dateset['Volume_ma'] = df_dateset['Volume'].rolling(window=window, min_periods=min_periods).mean()
# 移動平均を出せない行を省いてデータセットに代入する
df_dateset = df_dateset[int(window - 1):]
return df_dateset
def lag_dateset(shift, df_dateset):
# 2018/1/11から35日シフトする
df_dateset_shift = df_dateset.shift(shift)
# シフトしたデータを結合する
df_dateset = pd.merge(df_dateset, df_dateset_shift, right_index=True, left_index=True, suffixes=('', '_shift'))
# 35日シフトしたので2018/1/11~2018/3/4を除いた、2018/3/5からのデータを抽出する
df_dateset = df_dateset[shift:]
# 不要な列を削除する
df_dateset = df_dateset.drop(['Open', 'High', 'Low', 'Volume', 'Open_ma', 'High_ma', 'Low_ma', 'Close_ma', 'Volume_ma'], axis=1)
return df_dateset
def train_valid_split(df_dateset):
# 各列を標準化する
stdsc = StandardScaler()
columns_list = list(df_dateset.columns)
df_dateset[columns_list] = stdsc.fit_transform(df_dateset[columns_list])
# df_datesetを説明変数:xと目的変数:yに分割する
x = df_dateset.drop('Close', axis=1)
y = df_dateset['Close'].values
# 訓練データと検証データを分割するmdayを設定する
mday = pd.to_datetime('2020-11-11')
# 訓練データ用indexと検証データ用indexを作る
train_index = df_dateset.index < mday test_index = df_dateset.index >= mday
# 訓練データを作成する
x_train = x[train_index]
y_train = y[train_index]
# 検証データを作成する
x_test = x[test_index]
y_test = y[test_index]
# グラフ表示用の日付を抽出する
dates_test = x_test.index.values
return x_train, y_train, x_test, y_test, dates_test
def fit_predict_score(x_tr, y_tr, x_te, y_te, dates_test):
# アルゴリズムを設定する
alg = XGBRegressor(objective='reg:squarederror', random_state=123)
# 学習する
alg.fit(x_tr, y_tr)
# 予測する
y_pred = alg.predict(x_te)
# 評価する
r2 = r2_score(y_te, y_pred)
mae = mean_absolute_error(y_te, y_pred)
rmse = np.sqrt(mean_squared_error(y_te, y_pred))
'''
# 説明変数ごとの重要度を確認する
fig, ax = plt.subplots(figsize=(16, 8))
xgb.plot_importance(alg, ax=ax, height=0.8, importance_type='gain', show_values=False, title='重要度分析')
plt.savefig(f'重要度分析_r2_{r2:.4f}_mae_{mae:.4f}_rmse_{rmse:.4f}.png')
plt.show()
# 実データと予測データを比較する
fig, ax = plt.subplots(figsize=(16, 8))
ax.plot(dates_test, y_te, label='正解データ', c='k')
ax.plot(dates_test, y_pred, label='予測結果', c='r')
ax.grid()
ax.legend()
ax.set_title('終値の予測結果')
# x座標:2020年11月19日、y座標:2.1にscore_r2とscore_rmseを表示する
xdata = date2num(datetime(2020, 11, 15))
ax.text(xdata, 2.1, f'socre_R2:{r2:.4f}\nscore_MAE:{mae:.4f}\nscore_RMSE:{rmse:.4f}', size=15)
plt.savefig(f'終値の予測結果_r2_{r2:.4f}_mae_{mae:.4f}_rmse_{rmse:.4f}.png')
plt.show()
'''
return r2, mae, rmse
if __name__ == "__main__":
main()コードの補足
移動平均の範囲の説明
46行目で移動平均の範囲を指定しています。下記のようにrangeの範囲を(5, 20)とした場合、
for w in tqdm(range(5, 20))移動平均の設定を5,6,7,,,19で特徴量を作成し、それぞれで予測モデルを作成して検証を行います。合計15の予測モデルを作成することになります。
ラグ特徴の範囲の説明
50行目でラグ特徴の範囲を指定しています。下記のようにrangeの範囲を(5, 20)とした場合、
for l in tqdm(range(35, 50))ラグ特徴の設定を35,36,37,,,,49で特徴量を作成し、それぞれで予測モデルを作成して検証を行います。合計15の予測モデルを作成することになります。
上記の設定でプログラムを実行すると、移動平均の特徴量:15、ラグ特徴の特徴量:15で予測モデルを225(=15×15)個、作成します。範囲を広げるとプログラムの実行終了までに時間が掛かるので注意してください。
プログラムの実行結果
設定した移動平均、ラグ特徴で作成した予測モデルの学習、予測、評価を行い、その結果をプログラムを実行したカレントフォルダ、同じ場所にCSVファイルとして保存します。
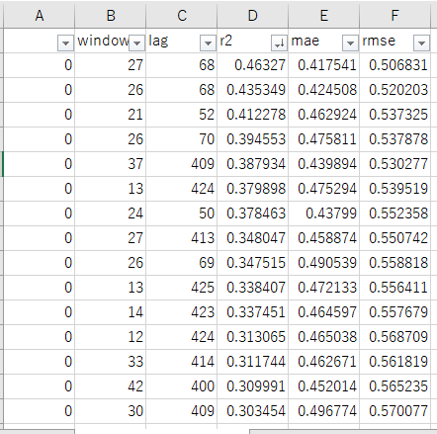
windowサイズ、lagサイズ、r2、mae、rmseのカラムを持ったCSVファイルが保存されます。
※エクセルで開き、r2で降順ソートしています。
145行目と167行目のコメントアウトを外すと、終値の予測結果と重要度分析のグラフを表示して、そのグラフ画像を保存します。
終値の予測結果
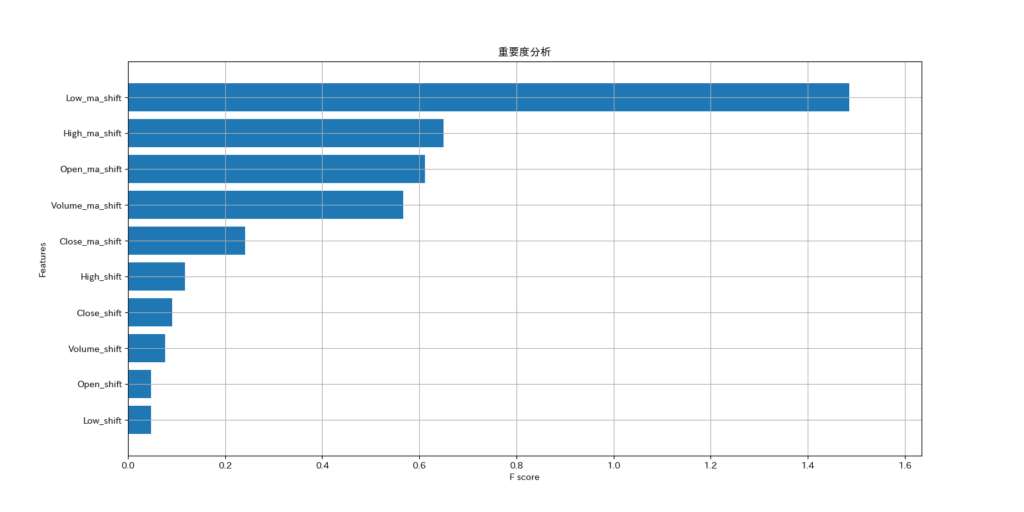
重要度分析のグラフ
予測結果について
重要度分析の結果から、予測にはラグ特徴より移動平均、特に低値の移動平均が最も影響を与えることが判りました。意外な結果でした。
次回、試したいこと
円ドル為替、日経平均、ダウ平均、NASDAQ総合などの外部データを増やして検証してみます。
今回は、XGBoostのハイパーパラメータを一切変更していません。GridSearchで最適なパラメータを検索してみます。


コメント