はじめに
競馬のレース結果をWebスクレイピングで取得しました。取得したレース結果をもとにXGBootでタイムを予測するモデルを作成してみました。
概要
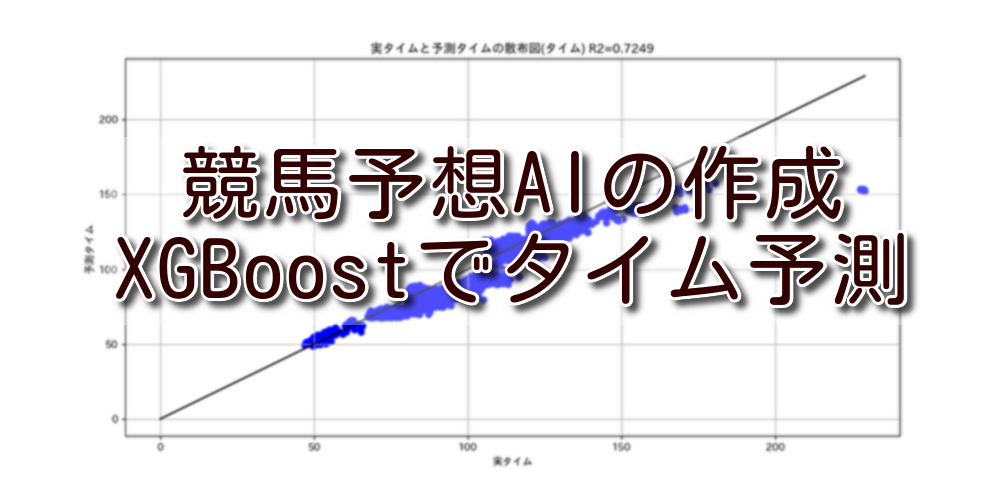
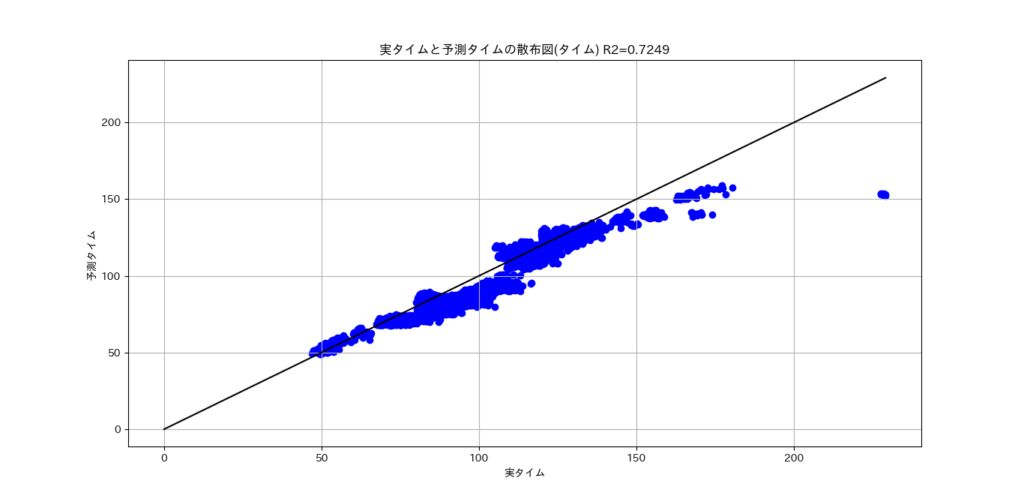
作成した予測モデルを評価した結果は下記のとおりです。R2の値が7割弱なので予測精度としては高いと思います。
<作成した予測モデルの評価結果>
| 評価項目 | 評価結果 |
| R2 | 0.724 |
| MAE | 7.779 |
| RMSE | 9.051 |
<実タイムと予測タイムの散布図>
<予測モデルの作成条件>
- 予測する値:各出走馬のタイム
- 予測に使用する訓練データ期間:2021/1~2021/11/30のレース結果
- 予測モデルを評価するデータ期間:2021/12/1~2022/12/31のレース結果
- 予測に使用する特徴量:馬名,性齢,斤量,騎手,単勝,人気,馬体重,距離,天候,馬場,状態,開催日,レース名,開催場所
予測に使用する特徴量について
競馬予想AIの作成(競馬データの取得③)で取得したデータを用います。
2021/1/1~12/31の間に開催された全国のレース情報から、馬名,性齢,斤量,騎手,単勝,人気,馬体重,距離,天候,馬場,状態,開催日,レース名,開催場所を抽出し、タイムの予測に使用します。
プログラム概要
プログラムの概要は下記となります。
| 該当行 | 概要 |
| 1~12 | ライブラリの読み込み |
| 15~16 | 取得したレース結果を読み込む |
| 18~58 | 読み込んだレース結果の欠損値、日付、タイムなどを整形する |
| 60~90 | 機械学習用の訓練データと検証データを生成する |
| 92~97 | 予測モデルの学習と予測を行う |
| 99~102 | モデルの評価値を算出する |
| 104~126 | 実タイムと予測タイムの散布図、重要度分析、予測タイムの保存を行う |
作成したプログラム
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.preprocessing import OrdinalEncoder
from sklearn.metrics import r2_score
from xgboost import XGBRegressor
import xgboost as xgb
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
# レース結果を読み込む
df_race_result = pd.read_csv('./2021_1_2021_12_レースの結果.csv', encoding='cp932')
# カラム名を設定する
df_race_result.columns = ['タイム', '馬名', '性齢', '斤量', '騎手', '単勝', '人気', '馬体重',
'距離', '天候', '馬場', '状態','開催日', 'レース名', '開催場所']
# 欠損している行を削除する
df_race_result = df_race_result.dropna()
# 馬体重が'計不'になっている行を削除する
drop_target = df_race_result.index[(df_race_result['馬体重'] == '計不')]
df_race_result = df_race_result.drop(drop_target)
# 行を削除したのでindexをリセットする
df_race_result = df_race_result.reset_index(drop=True)
# 開催日の型をobjectからdatetime64に変換する
df_race_result['開催日'] = pd.to_datetime(df_race_result['開催日'], format='%Y年%m月%d日')
# 分秒の表記を秒に変換する
time_list = []
df_time = df_race_result['タイム'].str.split(':')
for i in df_time:
times = float(i[0]) * 60 + float(i[1])
time_list.append(times)
df_times_list = pd.DataFrame(time_list)
df_race_result['タイム'] = df_times_list
# 馬体重の()を削除して現在の体重を取得する
weight_list = []
df_weight = df_race_result['馬体重'].str.split('(')
for i in df_weight:
weight = float(i[0])
weight_list.append(weight)
df_weight_list = pd.DataFrame(weight_list)
df_race_result['馬体重'] = df_weight_list
# 単勝の型をobjectからfloatに変換する
# 一部の値は'2,010.0'となっているので、'2010'に変換する
df_race_result = df_race_result.replace('2,010.0', '2010')
df_race_result['単勝'] = df_race_result['単勝'].astype(float)
# 入力データx、目的データyに分割
x = df_race_result.drop(['タイム'], axis=1)
y = df_race_result['タイム'].values
# 訓練データと検証データを分割する日付を設定する
mday = pd.to_datetime('2021-12-1')
# 訓練データと検証データを分割する
train_index = df_race_result['開催日'] < mday
test_index = df_race_result['開催日'] >= mday
# 入力データ、目的データを訓練データ用と検証データ用に分割する
x_train = x[train_index]
x_test = x[test_index]
y_train = y[train_index]
y_test = y[test_index]
# 日付データの分割
dates_test = df_race_result['開催日'][test_index]
# 訓練データと検証データをラベルエンコーディングする
oe_x_train = OrdinalEncoder()
x_train_encoded = oe_x_train.fit_transform(x_train) # Dataframeからndarrayに変わるとカラムがなくなり、
x_train_encoded = pd.DataFrame(x_train_encoded) # 特徴量分析で特徴量名がf0,f1,f2,,となるのでndarrayからDataframeに戻す
x_train_encoded.columns = list(x_train.columns.values) # カラムを付ける
oe_x_test = OrdinalEncoder()
x_test_encoded = oe_x_test.fit_transform(x_test) # Dataframeからndarrayに変わるとカラムがなくなり
x_test_encoded = pd.DataFrame(x_test_encoded) # 特徴量分析で特徴量名がf0,f1,f2,,となるのでndarrayからDataframeに戻す
x_test_encoded.columns = list(x_test.columns.values) # カラムを付ける
# モデルを設定
algorithm = XGBRegressor(object='reg:squarederror', random_state=123)
# 学習と予測
algorithm.fit(x_train_encoded, y_train)
y_pred = algorithm.predict(x_test_encoded)
# 評価 R2値/MAE/RMSEの計算
r2_score = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
# 実タイムと予測タイムを散布図で比較
plt.figure(figsize=(6, 6))
y_max = y_test.max()
plt.plot((0, y_max), (0, y_max), c='k')
plt.scatter(y_test, y_pred, c='b')
plt.xlabel('実タイム')
plt.ylabel('予測タイム')
plt.title(f'実タイムと予測タイムの散布図(タイム) R2={r2_score:.4f}')
plt.grid()
plt.show()
# 予測タイムに対する重要度分析
fig, ax = plt.subplots(figsize=(8, 4))
xgb.plot_importance(algorithm, ax=ax, height=0.8, importance_type='gain',
show_values=False, title='予測タイムの重要度分析')
plt.show()
# 予測タイムを保存する
df_race_result_predict = x_test.copy()
df_race_result_predict['実タイム'] = y_test
df_race_result_predict['予測タイム'] = y_pred
df_race_result_predict.to_csv('./予測結果.csv', encoding='cp932', errors='ignore')プログラムの補足
82~85行目でラベルエンコーディングを実施しています。
エンコード後はカラム名がリセットされるので、85行目でカラム名を再セットしています。
84行目を実行した直後のx_train_encodedの内容一部(カラム名がリセットされている)

85行目を実行した直後の内容一部(カラム名を再セット)
プログラムの実行結果
プログラムを実行すると下記3つ結果を出力します。
- 実タイムと予測タイムの散布図
- 予測タイムの重要度分析
- 検証データに予測タイムを追加したCSVファイルの出力
実タイムと予測タイムの散布図は概要に貼っていますので、そちらを参照してください。
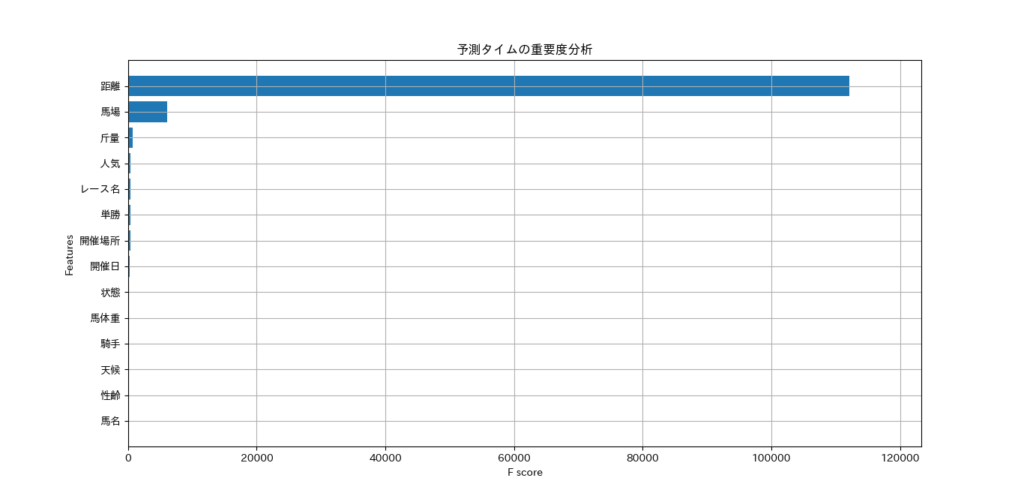
予測タイムの重要度分析は下記となります。
最も影響するのは「距離」となりました。この結果は想定とおりでした。次に影響しているのは「馬場」でした。「馬名」の影響は最も小さいのは意外でした。学習と検証に使用したデータ期間が1年だったからでしょうか。データ期間を10年などに増やして、重要度にどういった影響を与えるのかも検証してみます。
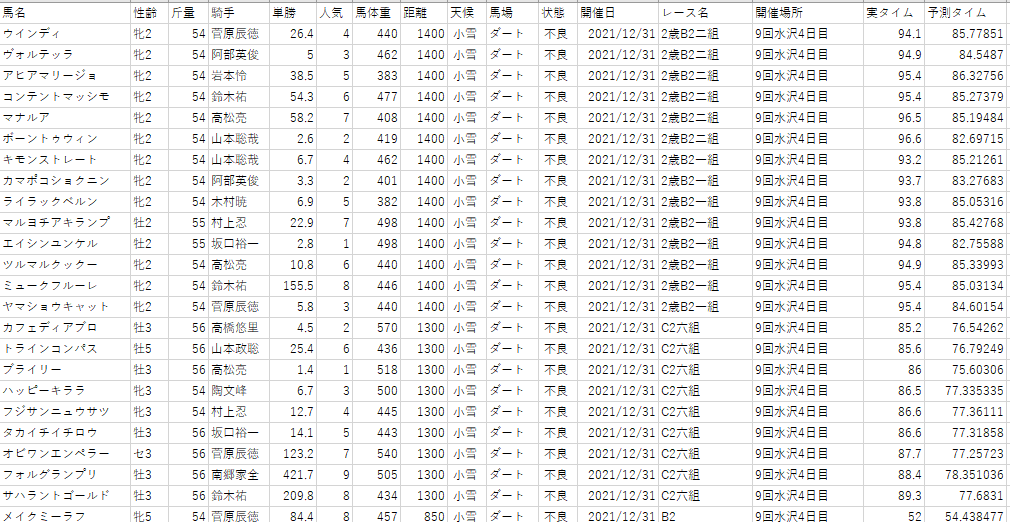
出力するCSVファイルは下記のように出力されます。
検証データに「実タイム」と「予測タイム」を追加したCSVファイルが出力されます。
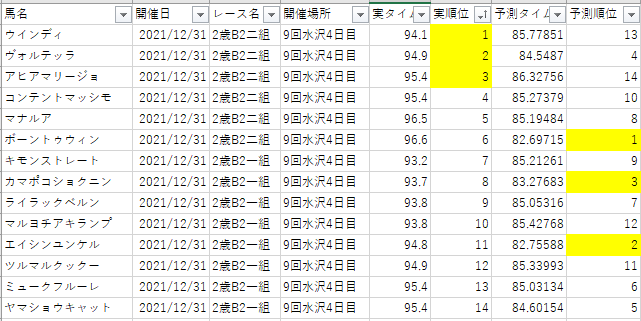
予測結果の確認
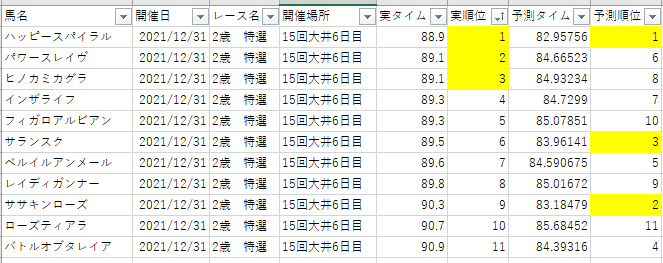
いくつかのレース結果を適当に抽出して、予測順位と実順位を比較してみました。
複勝狙いで、3着までの順位を比較しています。
3着までのセルを黄色しています。
「9回水沢4回目、2歳B2二組」の実順位と予測順位
- 予測:ハズレ
- 詳細:実順位が1位と3位の馬を、13位と14位と予測しており、大きく外している。
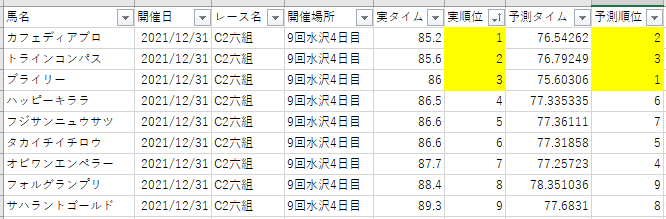
「9回水沢4回目、C2六組」の実順位と予測順位
- 予測:アタリ
- 詳細:予測は正確ではないが、3着以内の予測はできている
「15回大井6日目、2歳 特選」の実順位と予測順位
- 予測:ハズレ
- 詳細:1位の予測はできているが、2位と3位の予測は失敗している
「20回名古屋4日目、2歳6組」の実順位と予測順位
- 予測:アタリ
- 詳細:予測は正確ではないが、3着以内の予測はできている

次回、試したいこと
今回はデータ期間を1年で予測モデルを作成しました。データ期間を10年などに増やして予測モデルを作成してみます。また、手動で行っていた予測結果の確認をプログラムで処理するようにしてみます。


コメント
コメント失礼致します。
Webスクレイピング③でデータを取得後、投稿者様のコードを実行したところ、下記のエラーが出ました。
———————————————————————–
File “C:\Users\Desktop\Pythoncode\test.py”, line 68
train_index = df_race_result[‘開催日’] = mday
^
SyntaxError: invalid syntax
———————————————————————–
このエラーは改行をして自分で解決したのですが、
その後、再度投稿者様のコードを実行すると下記のような新しいエラーがでるようになりました。
・カラムを直接入力
・Windows,Macの二つのOSでそれぞれ実行
・Google colaboで実行
上3つのことを試してみましたが、全て同じエラーが出ている状態です。
8時間ほど試行錯誤してやってましたが、解決できませんでした。
もしよかったら、投稿者様で再度コードの実行などをしていただけないでしょうか。
宜しくお願い致します。
———————————————————————–
C:\Users\Desktop\Pythoncode>python keiba.py
Traceback (most recent call last):
File “C:\Users\Desktop\Pythoncode\keiba.py”, line 83, in
x_train_encoded = oe_x_train.fit_transform(x_train) # Dataframeからndarrayに変わるとカラムがなくなり、
File “D:\Python\lib\site-packages\sklearn\utils\_set_output.py”, line 142, in wrapped
data_to_wrap = f(self, X, *args, **kwargs)
File “D:\Python\lib\site-packages\sklearn\base.py”, line 859, in fit_transform
return self.fit(X, **fit_params).transform(X)
File “D:\Python\lib\site-packages\sklearn\preprocessing\_encoders.py”, line 1258, in fit
self._fit(X, handle_unknown=self.handle_unknown, force_all_finite=”allow-nan”)
File “D:\Python\lib\site-packages\sklearn\preprocessing\_encoders.py”, line 74, in _fit
X_list, n_samples, n_features = self._check_X(
File “D:\Python\lib\site-packages\sklearn\preprocessing\_encoders.py”, line 62, in _check_X
Xi = check_array(
File “D:\Python\lib\site-packages\sklearn\utils\validation.py”, line 931, in check_array
raise ValueError(
ValueError: Found array with 0 sample(s) (shape=(0,)) while a minimum of 1 is required.