はじめに
PythonとAIを学ぶために、株価の予測に挑戦しています。
そろそろ、新しいことにも挑戦したくなったので、競馬予測AIの作成に挑戦することにしました。
学習用データは、インターネットから取得します。
せっかくなので、Webスクレイピングについても挑戦します。
Webスクレイピングは、BeautifulSoup4を使用します。
競馬データの取得先
以下のページから競馬データを取得します。
プログラムの概要
指定したURLのHTMLを取得し、BeatifulSoupで取得したHTMLから必要なデータを抽出します。
| 該当行 | 概要 |
| 1~4 | ライブラリの読み込み |
| 6~14 | ネット競馬からデータを取得する |
| 16~43 | 取得したデータからレース情報と結果を抽出する |
| 45~50 | 抽出したデータをデータフレームに変換する |
| 53 | データフレームをCSVで保存する |
作成したプログラム
# 必要なライブラリを読み込む
import pandas as pd
import requests
from bs4 import BeautifulSoup
# 取得するデータのURLを指定する
url = 'https://db.netkeiba.com/race/202246042408/'
# 指定したURLからデータを取得する
res = requests.get(url)
# content形式で取得したデータをhtml形式で分割する
# text形式の場合、文字化けするのでcontent形式とする
soup = BeautifulSoup(res.content, 'html.parser')
# tableデータを抽出する
tables = soup.find('table', attrs={'class': 'race_table_01'})
tables = tables.find_all('tr')
# 取得したデータからindex名を抽出する
indexs = tables[0].text.split('\n')
tmp = []
# netkeibaの無料版では値が入っていないindexを削除する
for index in indexs:
if index not in ['', 'タイム指数', '調教タイム', '厩舎コメント', '備考']:
tmp.append(index)
# index名を設定する
df_index = pd.Series(tmp)
# 取得したデータから値を抽出する
data = []
tmp = []
df = pd.DataFrame()
df_tmp = pd.DataFrame()
# レース情報/結果を取得する
for table in tables[1:]:
tmp = table.text.split('\n')
df_tmp = pd.Series(tmp)
df = pd.concat([df, df_tmp], axis=1)
# 空行を削除する
df.drop(index=[0, 4, 6, 9, 11, 14, 15, 16, 17, 18, 19, 22, 26, 27, 28,
29, 30, 31, 32, 33, 34,35, 37, 38, 39, 41, 43, 44], axis=0, inplace=True)
# index名を設定する
df.index = df_index
# CSVに保存する
df.to_csv('レース情報と結果.csv', encoding='cp932')プログラムの実行結果
7行目で指定したページのHTMLを取得します。
取得するのは以下のページとなります。
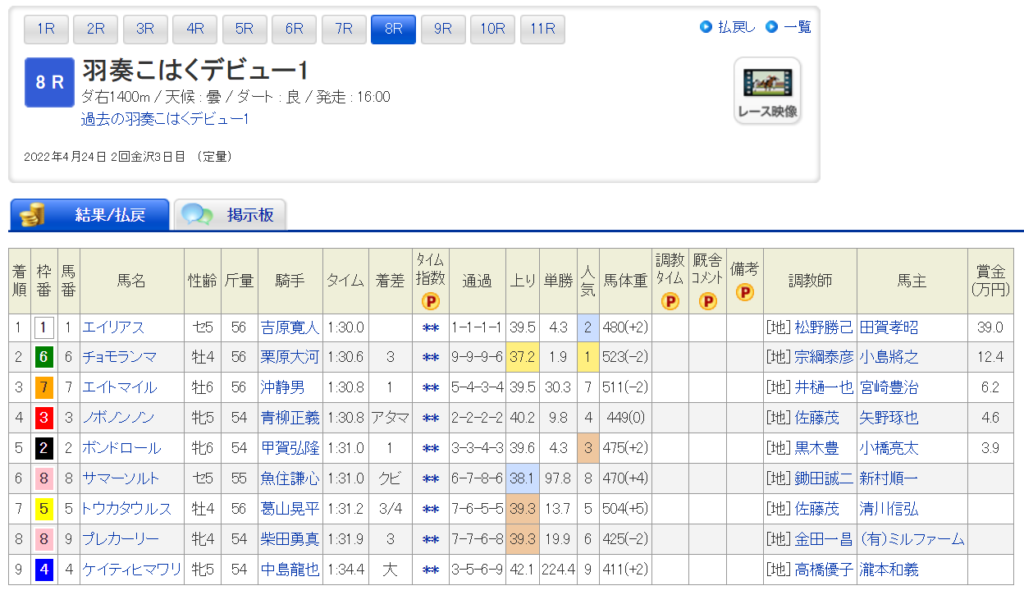
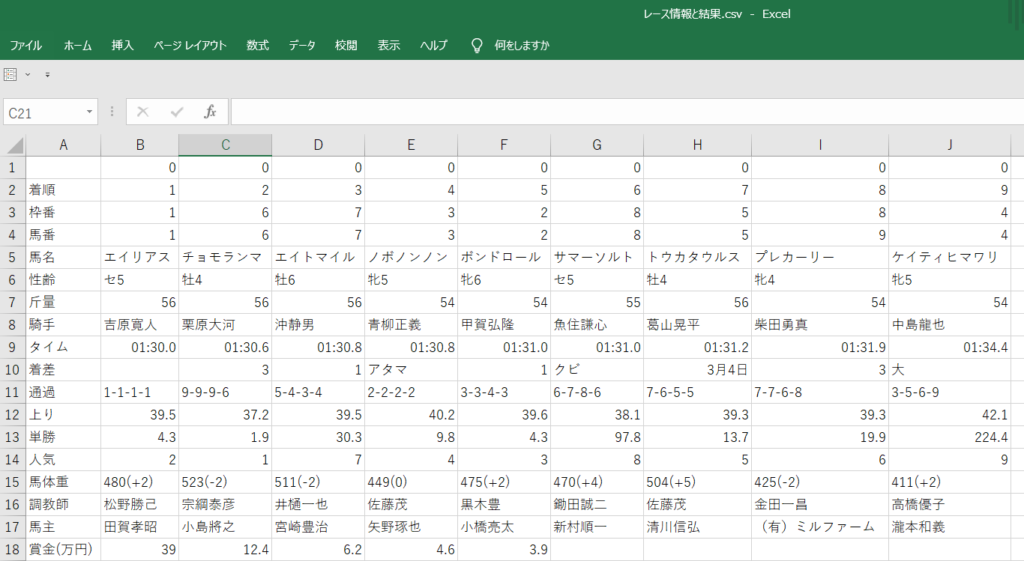
「レース情報と結果.csv」が出力されます。
CSVファイルの中身は以下となります。
次回、試すこと
まずは、1レース分のレース情報と結果を取得することができました。
2010年~2022年分のデータを自動で取得するプログラムを作成します。


コメント