はじめに
2021年度のAI Questに応募し、参加できることになりました。
最初の課題に、回帰モデルを用いた需要予測_在庫最適化_小売業を選択しました。
課題では、回帰モデルを用いた重要予測と在庫最適化を行うことになっていますが、
時系列モデルでも同様のモデルを作成して、精度を比較してみたいと思いました。
過去にKerasのLSTMを用いた株価予測を行う時系列モデルを作成したことがあり、どうせならLSTM以外を用いた方法で、もっと簡単に時系列モデルを作成できないか、精度の高いモデルを作成できないか、調査してみました。
Facebookが開発した「fbprophet」を見つけました。
クイックスタートマニュアルを見ると、コード作成の流れは
1.モデルを定義し、
2.そのモデルを学習(fit)させ、
3.予測(predict)する、
なので、scikit-learnのようなコード記載で精度の高い時系列モデルを作成できそうだったので、fbprophetを試すことにしました。
●Facebookの「fbprophet」の特徴
自動で下記を考慮して時系列モデルを作成してくれます。
- 年周期、週周期、日周期を考慮してくれる
- 休日や祝日の影響を考慮してくれる
- 過去のデータから季節効果の強弱を考慮してくれる
- データの欠落、トレンドの変化を考慮してくれる
- 外れ値を適切に扱ってくれる
Facebookの「fbprophet」を用いた株価の終値予測の時系列モデルを作成してみました。
結論から記載すると、作成したモデルは精度の低いモデルでした。
周期性の無い株価には、Facebookの「fbprophet」は不向きのようです。
fbprophetのインストール
fbprophetは、pystanを使用します。pystanは実行時にC++コンパイラを使用します。
事前にVisual Studio 2019 communityの「C++によるデスクトップ開発」をインストールしておきます。C++のインストールが終わったら、Python環境を立ち上げて、pipコマンドでpystanとfbprophetをインストールします。
pip install pystan==2.19.1.1
pip install fbprophetfbprophetをインストールした際に、下記の2つのエラーが出て、fbprophetのインストールに失敗することがありました。
<エラー1>
creating build\lib\prophet
creating build\lib\prophet\stan_model
Importing plotly failed. Interactive plots will not work.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_f5236004a3fd5b8429270d00efcc0cf9 NOW.
WARNING:pystan:MSVC compiler is not supported
stanfit4anon_model_f5236004a3fd5b8429270d00efcc0cf9_115203601789876019.cpp<エラー2>
error: command 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2019\\Community\\VC\\Tools\\MSVC\\14.29.30133\\bin\\HostX86\\x64\\cl.exe' failed with exit status 2<解決方法>
pystanをインストールしているPython環境によって発生するようです。
pystanをアンインストールし、バージョン2.17.1.0をインストールすることでエラーを解消することができました。
pip uninstall pystan
pip install pystan==2.17.1.0プログラムの動作概要
作成したプログラムの動作概要について下記に記載しました。
- ライブラリの読み込み(1~27行目)
- 株価の取得と加工(29~50行目)
- データを訓練データと検証データに分割(52~70行目)
- 時系列モデルを定義(72~76行目)
- 定義した時系列モデルを学習(78~79行目)
- 指定日数分の株価を予測(81~99行目)
- 学習済み時系列モデルの性能評価(101~114行目)
- 予測と性能評価の結果をグラフ表示(116~157行目)
プログラムのコード
作成したプログラムのコードは下記となります。
トヨタ自動車(証券コード:7203)の株価を予測する時系列モデルを作成してみました。
30行目で株価を取得しています。証券コードを変更することで、任意の株価を予測できるようになります。
# DataFrameのライブラリを読み込む
import pandas as pd
import pandas_datareader as web
import numpy as np
import math
# グラフ表示関連のライブラリを読み込む
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import japanize_matplotlib
from matplotlib.dates import date2num
# 日付を扱うためのライブラリを読み込む
from datetime import datetime
# fbprophetのライブラリを読み込む
from fbprophet import Prophet
# R2を計算するためのライブラリを読み込む
from sklearn.metrics import r2_score
# RMSEを計算するためのライブラリを読み込む
from sklearn.metrics import mean_squared_error
# 日本の祝日を取得するためのライブラリを読み込む
import jpholiday
# トヨタ自動車(証券コード:7203)の株価を取得する
df = web.DataReader('7203.JP', data_source='stooq', start='2015-01-01', end='2020-12-31')
# 項目名の日本語化
columns = ['開始値', '最高値', '最安値', '終値', '出来高']
# 項目名を日本語に置き換える
df.columns = columns
# 取得した株価を日付で昇順に変換する
df = df[::-1]
# dfはindexに日付を設定している
# df_1を新規に作成し、日付を列として追加する
df_1 = pd.DataFrame()
df_1['日付'] = df.index.values
# df_1に終値を追加する
df_1['終値'] = df.filter(['終値']).values
# 列名をfbprophetで扱える列名に変換する
df_1.columns = ['ds', 'y']
# 訓練データと検証データを分割する
# 訓練データ:2015-01-05 ~ 2020-11-09
# 検証データ:2020-11-10 ~ 2020-12-30
# 分割日sdayを設定する
split_day = pd.to_datetime('2020-11-10')
end_day = pd.to_datetime('2020-12-30')
# 分割日を起点にtrueとfalseを割り当てる
# train_indexは0~1426行目までTrueで、1427~1462行目までFalseとなり、
# test_indexは0~1426行目までFalseで、1427~1462行目までTrueとなる
train_index = df_1['ds'] < split_day test_index = df_1['ds'] >= split_day
# 訓練データと検証データを作成する
x_train = df_1[train_index]
x_test = df_1[test_index]
# 予測データと検証データをグラフ表示する際に使用する日付を設定する
# 設定する日付は2020-11-10 ~ 2020-12-30となる
dates_test = df_1['ds'][test_index]
# 時系列モデルを定義する
m1 = Prophet(yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=False,
seasonality_mode='multiplicative')
# 時系列モデルを学習する
m1.fit(x_train)
# 予測データを作成する
# 予測する期間は、2020-11-10から2020-12-30の51日分
future_1 = m1.make_future_dataframe(periods=51, freq='D')
# 土曜日=5、日曜日=6をfuture_1から除外する
future_no_weekend = future_1[future_1['ds'].dt.weekday < 5]
# jpholidayで、指定した期間の祝日を取得する
holidays = jpholiday.between(split_day, end_day)
# 祝日以外の日付を保存するデータフレームを用意しておく
future_no_holidays = future_no_weekend.copy()
# 祝日以外の日付を抽出する
for i, _ in enumerate(holidays):
future_no_holidays = future_no_holidays[future_no_weekend['ds'] != holidays[i][0]]
# 予測する
forecast = m1.predict(future_no_holidays)
# forecastから予測部分yhatのみ抽出する
# 2020-11-10から2020-12-30の期間で株取引が行われた日数は36日となる
ypred = forecast[-36:][['yhat']].values
# ytest:予測期間中の正解データを抽出する
ytest = x_test['y'].values
# R2値,RMSEを計算する
score_r2 = r2_score(ytest, ypred)
score_rmse = np.sqrt(mean_squared_error(ytest, ypred))
# R2,RMSEの計算結果を表示する
print(f'R2 score:{score_r2:.4f}')
print(f'RMSE score:{score_rmse:.4f}')
# 要素ごとのグラフを描画する
# トレンド、週周期、年周期を描画する
fig = m1.plot_components(forecast)
# 訓練データ・検証データ全体のグラフ化
fig, ax = plt.subplots(figsize=(10, 6))
# 予測結果のグラフ表示(prophetの関数)
m1.plot(forecast, ax=ax)
# タイトル設定など
ax.set_title('終値の予測')
ax.set_xlabel('日付')
ax.set_ylabel('終値')
# 時系列グラフを描画する
fig, ax = plt.subplots(figsize=(8, 4))
# グラフを描画する
ax.plot(dates_test, ytest, label='正解データ', c='k')
ax.plot(dates_test, ypred, label='予測結果', c='r')
# 日付目盛間隔を表示する
# 木曜日ごとに日付を表示する
weeks = mdates.WeekdayLocator(byweekday=mdates.TH)
ax.xaxis.set_major_locator(weeks)
# 日付表記を90度回転する
ax.tick_params(axis='x', rotation=90)
# 方眼表示、凡例、タイトルを設定する
ax.grid()
ax.legend()
ax.set_title('終値の予測')
# x座標:2020年11月19日、y座標:7800にscore_r2とscore_rmseを表示する
xdata = date2num(datetime(2020, 11, 19))
ax.text(xdata, 7800, f'socre_R2:{score_r2:.4f}\nscore_RMSE:{score_rmse:.4f}', size=15)
# ax.text(xdata, 6600, f'socre_RMSE:{score_rmse:.4f}', size=15)
# 画面出力
plt.show()プログラムコードの要点説明
プログラムコードの要点について説明します。
●時系列モデルの定義(72~76行目)
# 時系列モデルを定義する
m1 = Prophet(yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=False,
seasonality_mode='multiplicative')- 取得した株価は、2015年1月1日から2020年12月31日の日単位で5年分となります。
- 年、週の周期性を判断する材料が揃っているので、
「yearly_seasonality」と「weekly_seasonality」は「True」を設定しています。 - 時間の周期性を判断する材料は揃っていないので、
「daily_seasonality」は「False」に設定しています。 - モデルを作成する際の「seasonality_mode」は、加法モデル「additive」と乗法モデル「multiplicative」の2種類から選択できます。周期性に増加傾向がある場合は、乗法モデル「multiplicative」を選択すると精度が上がります。
2015年1月5日の株価は6704円、2020年11月10日は7267円、増加しているので乗法モデル「multiplicative」を選択します。
●指定日数分の株価を予測(81~99行目)
# 予測データを作成する
# 予測する期間は、2020-11-10から2020-12-30の51日分
future_1 = m1.make_future_dataframe(periods=51, freq='D')- 予測する未来の日時のデータフレームを作成するmake_future_dataframeメソッドが実行します。同メソッドを使用して作成されるのは、日時のデータフレームなので、自前で用意した時刻のデータフレームでも未来予測できました。
- 訓練データを2020年11月9日までに設定していたので、future_1には2020年11月10日~2020年12月31日までの日時が追加されます。
- periodで期間、freqで頻度を指定します。
<未来予測を365日とした場合>
例1.period=365,freq=’D’
例2.period=12,freq=’M’
# 土曜日=5、日曜日=6をfuture_1から除外する
future_no_weekend = future_1[future_1['ds'].dt.weekday < 5]- future_1には、株取引が行われてない週末の日付も含まれているので、土日を除外します。
- dt.weekdayメソッドを使用することで、月~日を0~6の数値として扱うことができます。0~4=月~金のデータを抽出します。
# jpholidayで、指定した期間の祝日を取得する
holidays = jpholiday.between(split_day, end_day)- future_no_weekendには、株取引が行われていない祝日の日付も含まれているので、祝日を除外します。
- jpholidayで、指定した期間の祝日を取得します。
# 祝日以外の日付を保存するデータフレームを用意しておく
future_no_holidays = future_no_weekend.copy()
# 祝日以外の日付を抽出する
for i, _ in enumerate(holidays):
future_no_holidays = future_no_holidays[future_no_weekend['ds'] != holidays[i][0]]- 祝日以外の日付を抽出します。
- holidaysはリストであり、中身は[(Timestamp(‘2020-11-23 00:00:00’), ‘勤労感謝の日’)]となっています。
- forループで日付だけを抜き出し、抜き出した日付と一致しない日付だけをfuture_no_holidaysに保存します。
●学習済み時系列モデルの性能評価(101~114行目)
# forecastから予測部分yhatのみ抽出する
# 2020-11-10から2020-12-30の期間で株取引が行われた日数は36日となる
ypred = forecast[-36:][['yhat']].values- 予測結果は、yhatに保存されています。
- 2020-11-10から2020-12-30の期間で株取引が行われた36日分のデータを抽出します。
# R2値,RMSEを計算する
score_r2 = r2_score(ytest, ypred)
score_rmse = np.sqrt(mean_squared_error(ytest, ypred))- R2値の計算には、sklearn.metricsのr2_scoreを使用します。
- RMSEの計算には、sklearn.metricsのmean_squared_errorを使用します。
# 要素ごとのグラフを描画する
# トレンド、週周期、年周期を描画する
fig = m1.plot_components(forecast)- prophet独自のplot_componentsメソッドを使用することで、トレンド、週周期、年周期を描画することができます。
プログラムの実行結果
プログラムが正常に実行されると、下記3つのグラフが表示されます。
- 2015年1月1日~2020年12月31日の終値予測
- 2015年1月1日~2020年12月31日のトレンド、週周期、年周期
- 2020年11月10日~2020年12月31日の予測データと実データの比較
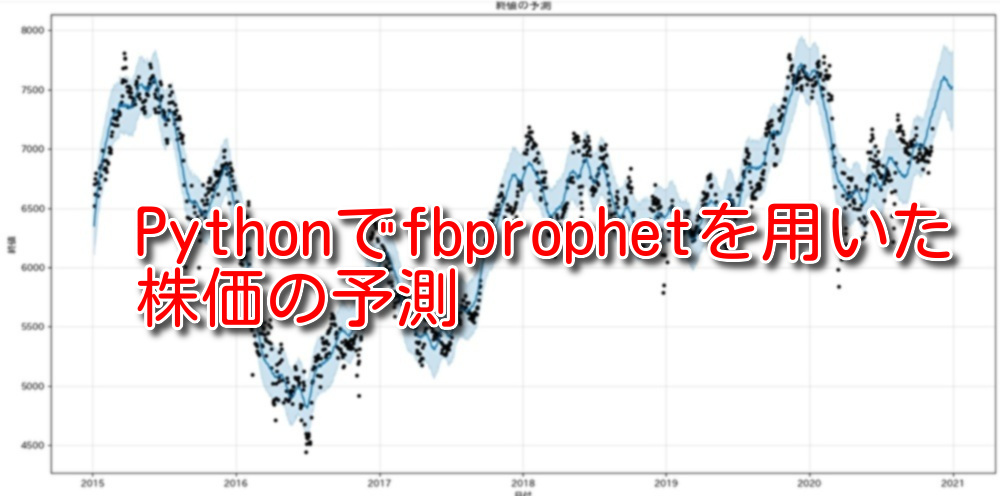
●2015年1月1日~2020年12月31日の終値予測
- 黒点:実際の終値です。
- 薄青の領域:予測した結果、80%の確率で薄青の領域に含まれる、ことを意味します。黒点が薄青の領域外に多数存在している場合は、そのモデルの予測精度は低い、ことを意味します。
- 青い線:薄青の領域で最も確率が高い値を繋げた線、となります。
薄青の領域外に黒点が散在しています。この時点で精度の高いモデルではないことが読み取れます。
●2015年1月1日~2020年12月31日のトレンド、週周期、年周期

- trend:長期トレンドを確認できます。
グラフから2019年3月ごろから傾きが少ないです。一定の増加傾向を示しています。 - weekly:週単位の周期性を確認できます。
土日は株取引がない(除外している)のでマイナスを示しています。 - yearly:年単位の周期性を確認できます。
1月から徐々に値を下げて5月が底値となり、12月まで徐々に値を上げていることを示しています。
長期トレンドを確認すると、上がったり下がったりしていることを確認できます。このような状態だと周期性を基に予測しているので、精度は期待できません。
●2020年11月10日~2020年12月31日の予測データと実データの比較
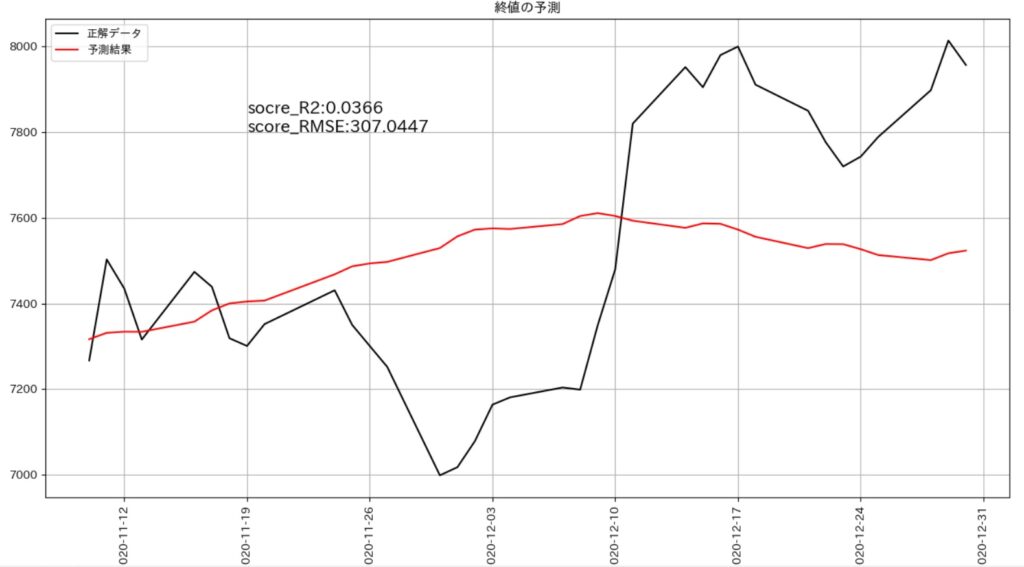
- 赤線が予測した終値、黒線が実際の終値、となります。
- 性能評価としてR2値とRMSE値をグラフに描画しています。
R2値は0.0366、RMSE値は307.0447でした。
R2値は1に近いほど、RMSE値は0に近いほど精度が高いことを意味しています。R2値の0.0366は、まったく予測ができていない数値です。
まとめ
fbprophetを使用することで、scikit-learnを使用するかのごとく、時系列モデルを作成できました。ただ、株価などの周期性の低い事柄を予測するのは向いていない、と感じました。
今後の検証について
検証したいことが3点あります。
- 時系列モデル作成時のパラメータチューニング
- 複数の要素を用いた時系列モデル作成と予測
- 任意のイベントを時系列モデルに組み込む
●1.時系列モデル作成時のパラメータチューニング
fbprophetには、過学習あるいは学習しきれない状況を回避するために、モデルを作成するときにトレンド変化への柔軟性を設定することができます。
グリッドサーチを用いてchangepoint_range、changepoint_prior_scale、interval_width、のモデル作成時の最適値を探索し、精度が上がるかを検証してみます。
●2.複数の要素を用いた時系列モデル作成と予測
KerasのLSTMを用いた時系列モデルを作成した際、複数の要素を用いることで、精度を上げることができました。fbprophetの時系列モデルを作成する際も、開始値、最高値、最安値、出来高を組み込んだ時系列モデルを作成し、精度が上がるかを検証してみます。また、同業他社の株価に連動する場合もあるので、要素として同業他社の株価を組み込んだ時系列モデルを作成し、精度が上がるかを検証してみます。
●3.任意のイベントを時系列モデルに組み込む
fbprophetには、「祝日」や「コンサート開催日」などの特定日をモデルに組み込むことができます。株に影響を与える下記の特定日を時系列モデルに組み込んで、精度が上がるかを検証してみます。
- 四半期決算
- 日米欧中央銀行の金融政策会議開催日
- 日米欧GDP速報値の発表日
- 日米欧CPI(消費者物価指数)の発表日


コメント