プログラムの説明
- 取得する株価情報はトヨタ(証券コード7203)
- 取得する期間は2020年1月1日から2020年12月31日(2020年の取引が行われた日は242日)
- 予測モデルを構築するためのライブラリは、KerasのLSTM
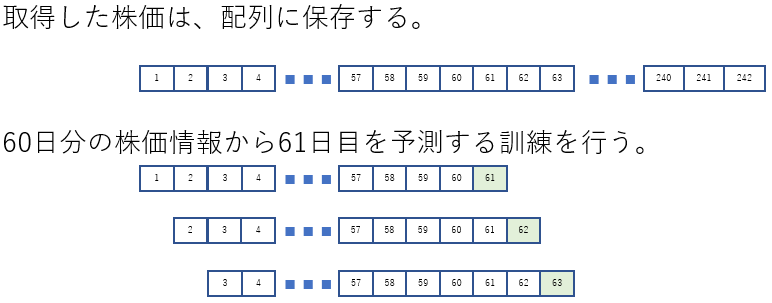
- 予測モデルの学習フローは、1日目から60日目の終値を読み込んで、61日目の終値を予測する
- 予測モデルの層は、2層
- 予測モデルの学習で使用する最適化関数は、adam
- 予測モデルの学習で使用する損失関数は、最小2乗誤差
- 予測モデルの精度評価方法は、決定係数と平均二乗誤差の平方根(RMSE)の2つ
- 予測モデルの精度評価方法で使用する関数は、scikit-learnのr2_scoreとmean_squared_error
補足
プログラムの動作概要
- ライブラリの読み込み
- 株価を取得する
- 取得した株価を整形する
- 株価を正規化する
- 正規化した株価を訓練データと検証データに分割する
- 訓練データを学習用途に整形する
- 予測モデルを定義する
- 定義した予測モデルをコンパイルする
- 検証データでコンパイルした予測モデルの検証を行う
- 検証した結果を評価する
- 予測結果と評価結果を表示する
コード
# 警告を無視する
import warnings
warnings.filterwarnings('ignore')
# ライブラリを読み込む
import math
import pandas_datareader as web
import numpy as np
# kerasのライブラリを読み込む
from keras.models import Sequential
from keras.layers import Dense, LSTM
# scikit-learnの正規を行うライブラリを読み込む
from sklearn.preprocessing import MinMaxScaler
# scikit-learnで決定係数とRMSEの計算を行うライブラリを読み込む
from sklearn.metrics import r2_score, mean_squared_error
# グラフ表示のライブラリとグラフ表示で日本語を表示するためのライブラリを読み込む
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import japanize_matplotlib
# トヨタ(証券コード:7203)の株価を取得する
df = web.DataReader('7203.JP', data_source='stooq', start='2020-01-01', end='2020-12-31')
# 取得した株価を日付で昇順に変換する
df = df[::-1]
# 取得した株価データを終値以外を除外する
data = df.filter(['Close'])
# 取得した株価データの終値をdatasetに代入する
dataset = data.values
# 取得した株価データの8割を訓練データとする
# math.ceil : 小数点以下を切り上げ
# traing_data_lenは194となる
training_data_len = math.ceil(len(dataset) * .8)
# 最小値:5839->0、最大値:8014->1となるように正規化する
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(dataset)
# 正規化したデータから訓練で使用する行数分のデータを抽出する
# 0番から193番までが訓練で使用するデータとなる
train_data = scaled_data[0:training_data_len, :]
# 訓練データと正解データを保存する配列を用意する
# x_train:訓練データ
# y_train:正解データ
x_train = []
y_train = []
# 訓練データとして60日分のデータをx_train[]に追加する
# 正解データとして61日目のデータをy_train[]に追加する
for i in range(60, len(train_data)):
x_train.append(train_data[i - 60:i, 0])
y_train.append(train_data[i, 0])
# Convert the x_train and y_train to numpy arrays
# 訓練データと教師データをNumpy配列に変換する
x_train, y_train = np.array(x_train), np.array(y_train)
# 訓練データのNumpy配列について、奥行を訓練データの数、行を60日分のデータ、列を1、の3次元に変換する
x_train_3D = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
# LSTMモデルを定義する
n_hidden = 50 # 隠れ層の数
units1 = 25 # 第1層の出力数
units2 = 1 # 第2層の出力数
model = Sequential()
model.add(LSTM(n_hidden, return_sequences=True, input_shape=(x_train_3D.shape[1], 1)))
model.add(LSTM(n_hidden, return_sequences=False))
model.add(Dense(units1))
model.add(Dense(units2))
# 定義したLSTMモデルをコンパイルする
# 最適化手法:adam
# 損失関数:最小2乗誤差
model.compile(optimizer='adam', loss='mean_squared_error')
# コンパイルしたモデルの学習を行う
batch_size = 1 # バッチサイズ
epochs = 1 # 訓練の回数
model.fit(x_train_3D, y_train, batch_size=batch_size, epochs=epochs)
# 検証データを用意する
# 194番から241番までをテストデータとする
# 最初の194番をテストするためには、134番~193番の終値の株価データが必要となる
# 検証データの最初の番は、訓練データの最後から60を引いた134番となる
# 検証データの総番数は108となる
test_data = scaled_data[training_data_len - 60:, :]
# x_test:検証データ
# y_test:正解データ
x_test = []
y_test = scaled_data[training_data_len:, :]
# 検証データをセットする
for i in range(60, len(test_data)):
x_test.append(test_data[i - 60:i, :])
# 検証データをNumpy配列に変換する
x_test = np.array(x_test)
# 検証データのNumpy配列について、奥行を訓練データの数、行を60日分のデータ、列を1、の3次元に変換する
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
# モデルに検証データを代入して予測を行う
predictions = model(x_test)
# 予測データをNumpy配列に変換する
predictions = np.array(predictions)
# モデルの精度を評価する
# 決定係数とRMSEを計算する
# 決定係数は1.0に、RMSEは0.0に近いほど、モデルの精度は高い
r2_score = r2_score(y_test, predictions)
rmse = np.sqrt(mean_squared_error(y_test, predictions))
print(f'r2_score: {r2_score:.4f}')
print(f'rmse: {rmse:.4f}')
# 予測データは正規化されているので、元の株価に戻す
predictions = scaler.inverse_transform(predictions)
# 訓練の価格、実際の価格、予測の価格をグラフで表示する
train = data[:training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
# グラフを表示する領域をfigとする
fig = plt.figure(figsize=(12, 6))
# グラフ間の余白を設定する
fig.subplots_adjust(wspace=0.6, hspace=0.2)
# GridSpecでfigを縦10、横15に分割する
gs = gridspec.GridSpec(9, 14)
# 分割した領域のどこを使用するかを設定する
# gs[a1:a2, b1:b2]は、縦の開始位置(a1)から終了位置(a2)、横の開始位置(b1)から終了位置(b2)
ax1 = plt.subplot(gs[0:8, 0:8])
ax2 = plt.subplot(gs[0:5, 9:14])
# 1番目のグラフを設定する
ax1.set_title('終値の履歴と予測結果', fontsize=16)
ax1.set_xlabel('日付', fontsize=12)
ax1.set_ylabel('終値 円', fontsize=12)
ax1.plot(df['Close'])
ax1.plot(valid[['Predictions']])
ax1.legend(['実際の価格', '予測の価格'], loc='lower right')
ax1.grid()
# 2番目のグラフを設定する
ax2.set_title('予測の価格と実際の価格の散布図表示', fontsize=16)
ax2.set_xlabel('予測の価格', fontsize=12)
ax2.set_ylabel('実際の価格', fontsize=12)
ax2.scatter(valid['Close'], valid['Predictions'], label=f'r2_score: {r2_score:.4f} \n rmse: {rmse:.4f}')
ax2.plot(valid['Close'], valid['Close'], 'k-')
ax2.legend()
ax2.grid()
fig.savefig('img.png')
plt.show()実行結果
コードを実行すると作成した予測したモデルについて、下記2つの情報を確認できます。
- 標準出力に性能評価のr2_scoreとrmseの計算結果が表示されます。
- 「終値の履歴と予測結果」と「予測の価格と実際の価格の散布図表示」の画像が表示されます。
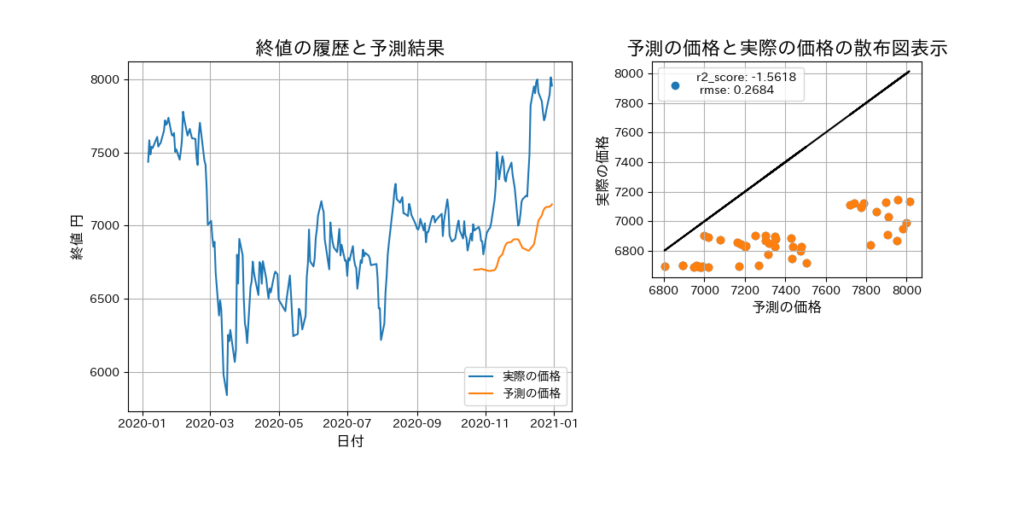
「予測の価格と実際の価格の散布図表示」の黒直線にオレンジ色の点が近ければ近いほど、精度が高い予測モデルを作成できたことになります。オレンジ色の点の多くは、黒直線の下にあります。これは、実際の価格より低い価格を予測していることを示しています。「終値の履歴と予測結果」を確認すると、予測の価格は実際の価格より下となっています。
決定係数(r2_score)について
実際の価格と予測の価格が全て一致する場合、その値は1になります。1に近ければ近いほど作成した予測モデルの精度は高いことになります。
平均二乗誤差の平方根(RMSE)について
実際の価格と予測の価格が近ければ近いほど、その値は0に近づきます。0に近ければ近いほど作成した予測モデルの精度は高いことになります。
r2_score:-1.5618、rmse:0.2684なので、使えないレベルの予測モデルとなります。
各パラメータの調整が必要です。
各パラメータの調整
調整できるパラメータは、活性化関数、最適化関数、損失関数、隠れ層の数、層ごとの出力数、バッチサイズ、エポック数、などの様々なパラメータがあります。下記のパターンで予測モデルの精度を確認してみました。初期の値から変更したパラメータを太字にしています。パターン7が最も精度が高い組み合わせでした。
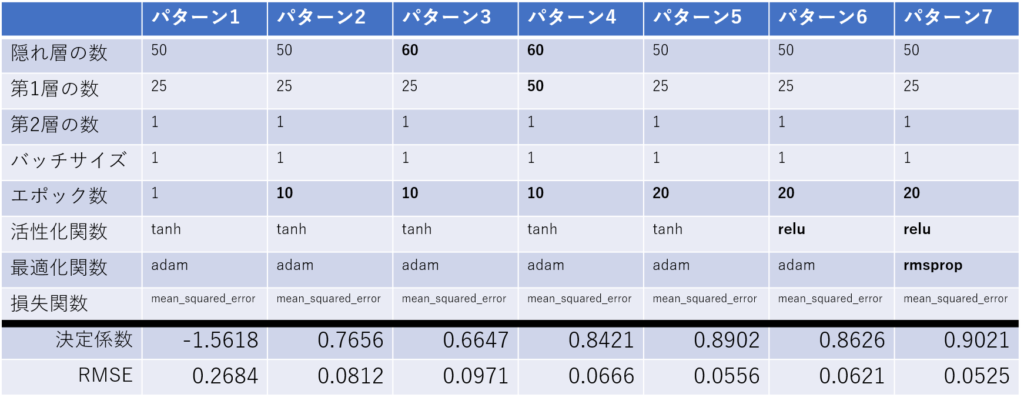
パターン7の結果表示
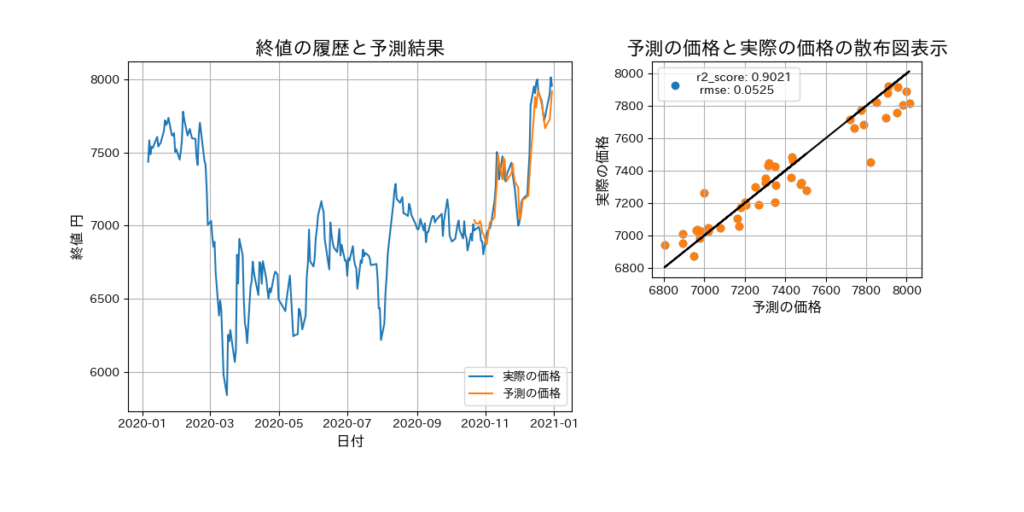
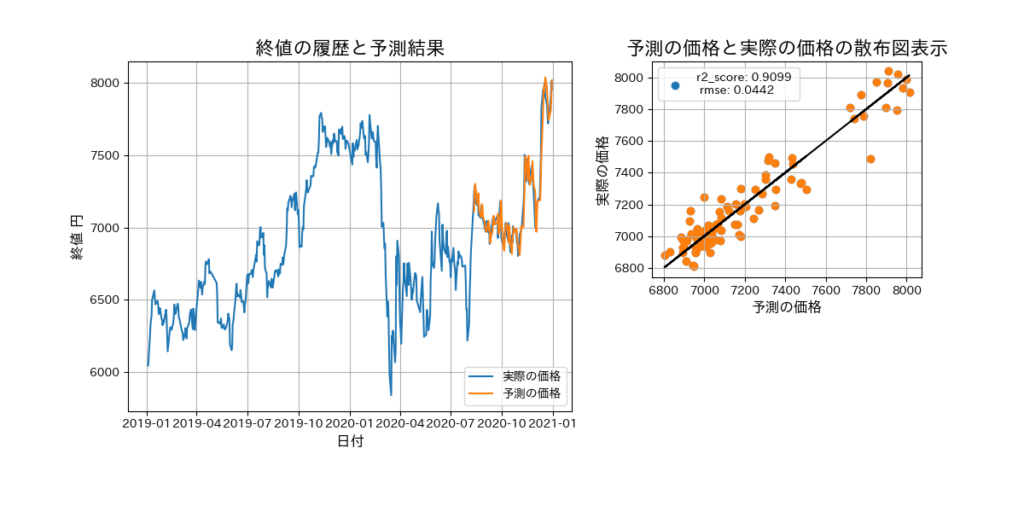
パターン7のパラメータと、取得する株価情報の期間を1年増やして2019-01-01から2020-12-31で予測モデルを作成すると、若干の精度向上がありました。
次に試したいこと
試したいことは下記の2つ。
- 作成したプログラムの入力変数は終値のみです。関連する変数、たとえば同業他社の株価情報や日経平均などを予測モデルを作成するときに使用して、精度の向上が図れるかを検証してみます。
- 作成したプログラムの予測範囲は、1日先のみです。予測範囲を増やし、たとえば30日後の予測データを計算できるようなプログラムを作成してみます。
以上です。


コメント