
結論
- tf.random.set_seed を使用するhttps://www.tensorflow.org/api_docs/python/tf/random/set_seed
経緯
機械学習のモデルを作成する際、モデルの精度を上げるために各種パラメータを変更します。同じパラメータでもモデルの精度が異なります。これは、モデルを作成する際の「重み」などの初期値が乱数で割り当るため発生します。各種パラメータを変更したことによる精度の変化なのか、「重み」などの初期値が異なることによる精度の変化なのか、判断できません。
乱数を固定することで、モデル作成時の「重み」などの初期値を固定にすることができないか。
方法を調べてみました。
方法
機械学習のモデルを作成するプログラムに下記を追記することで「重み」などの初期値を固定することができます。
# tensorflowのライブラリを読み込む
import tensorflow as tf
# 乱数シードを固定する
tf.random.set_seed(1234)検証
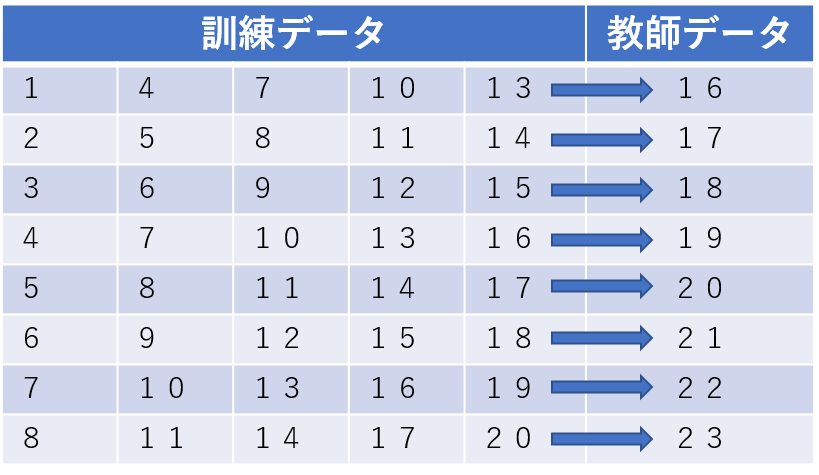
シンプルなLSTMを用いた時系列の機械学習モデルを作成します。作成するモデルは、5つの数字から次の数字を予測します。訓練データと教師データは下記の通り。
検証データと正解データは下記の通り。

予測結果が「27」に近ければ近いほど、精度の高いモデルとなります。
精度については、RMSEでも計算します。
コード
import numpy as np
# tensorflowのライブラリを読み込む
import tensorflow as tf
# 乱数シードを固定する
tf.random.set_seed(1234)
# kerasのライブラリを読み込む
from keras.models import Sequential
from keras.layers import Dense, LSTM
# RMSEを計算するためにsklearnのライブラリを読み込む
from sklearn.metrics import mean_squared_error
# 訓練データを用意する
x_train = np.array([
[1, 4, 7, 10, 13],
[2, 5, 8, 11, 14],
[3, 6, 9, 12, 15],
[4, 7, 10, 13, 16],
[5, 8, 11, 14, 17],
[6, 9, 12, 15, 18],
[7, 10, 13, 16, 19],
[8, 11, 14, 17, 20]])
# 教師データを用意する
y_train = np.array([16, 17, 18, 19, 20, 21, 22, 23])
# 訓練データと教師データをLSTMで読み込める形式に変換する
x_train = x_train.reshape((x_train.shape[0], x_train.shape[1], 1))
y_train = y_train.reshape((y_train.shape[0], 1, 1))
# モデルを定義する
model = Sequential()
model.add(LSTM(100, activation='relu', return_sequences=False, input_shape=(5, 1)))
model.add(Dense(1))
# モデルを作成する
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルを訓練する
model.fit(x_train, y_train, epochs=300, verbose=1)
# 検証データを用意する
x_test = np.array([12, 15, 18, 21, 24])
x_test = x_test.reshape((1, 5, 1))
# 正解データを用意する
y_test = np.array([27])
# 検証データを用いて予測する
y_predict = model.predict(x_test)
# 予測データを表示する
print(f'予測結果: {y_predict}')
# モデルの精度を評価する
# RMSEを計算する。RMSEは0.0に近いほど、モデルの精度は高い
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
print(f'rmse: {rmse:.4f}')実行結果
予測結果: [[27.314367]]
rmse: 0.3144乱数を固定しているので、繰り返し実行しても「予測結果」と「RMSE」の値は一定になります。


コメント