はじめに
AutoMLのpycaretでモデルの自動作成を試みましたが、特徴量のサイズが大きすぎてメモリ不足で作成に失敗しました。。。
モデルの自動作成は保留にして、モデルの精度を上げるために、Optunaでハイパーパラメータの調整に挑戦してみました。精度は上がりましたが、三連符の的中率の向上には至りませんでした。
概要
実施した作業概要のイメージは下記となります。

- レース結果は前回使用したデータと同じものを使用します。
- モデルの評価方法は、RMSEです。
- モデルはXGBoostで作成します。
プログラム概要
| 該当行 | 概要 |
| 1~24行 | ライブラリの読み込み |
| 27行 | メイン関数の開始位置 |
| 29行 | 全レースの情報を読み込む |
| 32行 | 読み込んだデータを説明変数x(距離、馬場、開催場所など)、目的変数y(タイム)に整形する |
| 36~37行 | 訓練データと評価データに分割する(概要の①に該当) |
| 40行 | 読み込んだデータをワンホットエンコード(OneHotEncode)する |
| 43行 | 訓練データと検証データに分割する(概要の②に該当) |
| 46行 | 読み込んだデータをdmatrixに変換する |
| 50~52行 | optunaでハイパーパラメータの調整を行い、最適なパラメータでモデルを作成する(概要の③に該当) |
| 55行 | 作成したモデルでタイムを予測する(概要の④に該当) |
| 58~61行 | R2、MAE、RMSEで評価する(概要の⑤に該当) |
| 64行 | 実タイムと予測タイムを散布図で比較する |
| 67行 | 予測タイムに対する重要度分析 |
| 70行 | 予測タイムをCSVで保存する |
| 73行 | ハイパーパラメータの最適化の結果を表示する |
| 76~263行 | 自作の関数 |
作成したプログラム
# 数値解析用のライブラリ
import numpy as np
import pandas as pd
# エンコード用のライブラリ
from sklearn.preprocessing import OrdinalEncoder
# xgboostのライブラリ
import xgboost as xgb
# 訓練データとモデル評価用データに分けるライブラリ
from sklearn.model_selection import train_test_split
# ハイパーパラメータチューニング自動化ライブラリ
import optuna
# R2,MAE,RMSEの計算用ライブラリ
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
# グラフ作成用のライブラリ
import matplotlib.pyplot as plt
import japanize_matplotlib
def main():
# データを読み込む
df_race_result = read_data()
# 説明変数x,目的変数yに整形する
x, y = format_data(df_race_result)
# 訓練データと評価データに分割する
# 分割する日はdayで指定する
day = '2022-5-21'
x_train, x_test, y_train, y_test = split_training_evaluation_data(x, y, day)
# データをエンコードする
x_train_encoded, x_test_encoded = encode_data(x_train, x_test)
# 訓練データと検証データに分割する
x_train, x_eval, y_train, y_eval = split_training_validation_data(x_train_encoded, y_train)
# データをdmatrixに変換する
dtrain, deval, dtest = convert_dmatrix(x_train, x_eval, x_test_encoded, y_train, y_eval, y_test)
# studyインスタンスを作成し、studyインスタンスを最適化する
# timeoutで最適化を行う時間に制限を設ける
objective = Objective(dtrain, deval, dtest, y_test)
study = optuna.create_study()
study.optimize(objective, timeout=60)
# タイムを予測する
time_predict, gbm = predict_time(study, dtrain, deval, dtest)
# 評価 R2,MAE,RMSEの計算
r2, mae, rmse = evaluate(y_test, time_predict)
print('r2:', r2)
print('mae:', mae)
print('rmse:', rmse)
# 実タイムと予測タイムを散布図で比較
create_scatter_plot(y_test, time_predict, r2)
# 予測タイムに対する重要度分析
create_importance_analysis(gbm)
# 予測タイムを保存する
save_predict_results(x_test, y_test, time_predict)
# ハイパーパラメータの最適化の結果
print('ハイパーパラメータの最適値:', study.best_params)
# データを読み込む
def read_data():
# 整形されたレース結果を読み込む
df = pd.read_csv('C:\\Users\\sakurater\\df_race_result.csv', encoding='cp932')
# 開催日の型をdate型に変換する
df['開催日'] = pd.to_datetime(df['開催日'])
return df
# 説明変数x、目的変数yに整形する
def format_data(df):
x = df.drop(['タイム'], axis=1)
y = df['タイム'].values
# カラム名を英語に変換する
x.columns = ['horse', 'age', 'rider_weight', 'rider', 'win', 'popular',
'horse_weight', 'distance', 'weather', 'ground', 'condition',
'date', 'race_name', 'location']
return x, y
# 訓練データと評価データに分割する
def split_training_evaluation_data(x, y, day):
# 訓練データと評価データを分割する日付を設定する
mday = pd.to_datetime(day)
# 訓練データと評価データを分割する
train_index = x['date'] < mday test_index = x['date'] >= mday
# 説明変数xと目的変数yを訓練データ用と評価データ用に分割する
x_train = x[train_index]
x_test = x[test_index]
y_train = y[train_index]
y_test = y[test_index]
return x_train, x_test, y_train, y_test
# データをラベルエンコードする
def encode_data(train, test):
# 訓練データのラベルエンコード
oe_x_train = OrdinalEncoder()
x_train_encoded = oe_x_train.fit_transform(train) # Dataframeからndarrayに変わるとカラムがなくなり、
x_train_encoded = pd.DataFrame(x_train_encoded) # 特徴量分析で特徴量名がf0,f1,f2,,となるのでndarrayからDataframeに戻す
x_train_encoded.columns = list(train.columns.values) # カラムを付ける
# 評価データのラベルエンコード
oe_x_test = OrdinalEncoder()
x_test_encoded = oe_x_test.fit_transform(test) # Dataframeからndarrayに変わるとカラムがなくなり、
x_test_encoded = pd.DataFrame(x_test_encoded) # 特徴量分析で特徴量名がf0,f1,f2,,となるのでndarrayからDataframeに戻す
x_test_encoded.columns = list(test.columns.values) # カラムを付ける
return x_train_encoded, x_test_encoded
# 訓練データと検証データに分割する
def split_training_validation_data(x, y):
# 訓練データをさらに、8:2の割合で訓練データと検証データを分割する
x_train, x_eval, y_train, y_eval = train_test_split(x, y, test_size=0.2, random_state=0)
return x_train, x_eval, y_train, y_eval
# xgboostを実行するには特殊なmatrixにする必要がある
def convert_dmatrix(x_train, x_eval, x_test_encoded, y_train, y_eval, y_test):
# dtrain:訓練データ,deval:検証データ,dtest:評価データ
dtrain = xgb.DMatrix(x_train, label=y_train)
deval = xgb.DMatrix(x_eval, label=y_eval)
dtest = xgb.DMatrix(x_test_encoded, label=y_test)
return dtrain, deval, dtest
# ハイパーパラメータ探索
class Objective:
def __init__(self, dtrain, deval, dtest, y_test):
# 変数X, yの初期化
self.dtrain = dtrain
self.deval = deval
self.dtest = dtest
self.y_test = y_test
def __call__(self, trial):
params = {'silent': 0,
'max_depth': trial.suggest_int('max_depth', 6, 9),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10),
'eta': trial.suggest_loguniform('eta', 0.01, 1.0),
'subsample': trial.suggest_uniform('subsample', 0.0, 1.0),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.0, 1.0),
'alpha': trial.suggest_loguniform('alpha', 0.01, 10.0),
'lambda': trial.suggest_loguniform('lambda', 0.01, 10.0),
'gamma': trial.suggest_loguniform('gamma', 0.01, 10.0),
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'tree_method': 'gpu_hist', # gpuを使う設定
'predictor': 'gpu_predictor', # gpuを使う設定
'verbose': -1}
gbm = xgb.train(params,
self.dtrain,
num_boost_round=10000,
early_stopping_rounds=10,
evals=[(self.deval, 'eval')] # 検証データで評価する
)
# 評価データでタイムを予測し、RMSEを計算する
predicted = gbm.predict(self.dtest)
RMSE = np.sqrt(mean_squared_error(self.y_test, predicted))
# 最適化処理に「枝刈り(pruning)」を含める
pruning_callback = optuna.integration.XGBoostPruningCallback(trial, 'rmse')
return RMSE
def predict_time(study, dtrain, deval, dtest):
# 最適時のハイパーパラメータでモデルを作成する
# paramsに最適時のハイパーパラメータを設定する
params = {'silent': 0,
'max_depth': study.best_params['max_depth'],
'min_child_weight': study.best_params['min_child_weight'],
'eta': study.best_params['eta'],
'subsample': study.best_params['subsample'],
'colsample_bytree': study.best_params['colsample_bytree'],
'alpha': study.best_params['alpha'],
'lambda': study.best_params['lambda'],
'gamma': study.best_params['gamma'],
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'tree_method': 'gpu_hist',
'predictor': 'gpu_predictor',
'verbose': -1}
# 学習、評価を行う
gbm = xgb.train(params,
dtrain,
num_boost_round=10000,
early_stopping_rounds=10,
evals=[(deval, 'eval')]
)
# タイムを予測
time_predict = gbm.predict(dtest)
return time_predict, gbm
# 評価 R2,MAE,RMSEの計算
def evaluate(y_test, time_predict):
r2 = r2_score(y_test, time_predict)
mae = mean_absolute_error(y_test, time_predict)
rmse = np.sqrt(mean_squared_error(y_test, time_predict))
return r2, mae, rmse
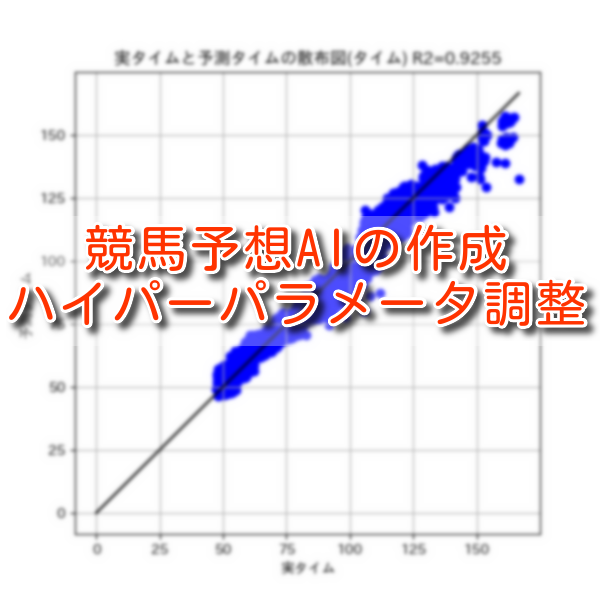
# 実タイムと予測タイムを散布図で比較
def create_scatter_plot(y_test, time_predict, r2):
plt.figure(figsize=(6, 6))
y_max = y_test.max()
plt.plot((0, y_max), (0, y_max), c='k')
plt.scatter(y_test, time_predict, c='b')
plt.xlabel('実タイム')
plt.ylabel('予測タイム')
plt.title(f'実タイムと予測タイムの散布図(タイム) R2={r2:.4f}')
plt.grid()
plt.show()
# 予測タイムに対する重要度分析
def create_importance_analysis(model):
fig, ax = plt.subplots(figsize=(8, 4))
xgb.plot_importance(model, ax=ax, height=0.8, importance_type='gain',
show_values=False, title='予測タイムの重要度分析')
plt.show()
# 予測タイムを保存する
def save_predict_results(x_test, y_test, time_predict):
df_race_result_predict = x_test.copy()
df_race_result_predict['time'] = y_test
df_race_result_predict['time_predict'] = time_predict
df_race_result_predict.to_csv('./予測結果.csv', encoding='cp932', errors='ignore')
if __name__ == "__main__":
main()プログラムの補足
ハイパーパラメータの最適化を行う上限を、回数ではなく時間で設定しています。
回数で3000回を設定した際、50時間以上経過しても最適化が終わらないことがありました。
そのため時間で設定することにしました。設定箇所は52行です。
study.optimize(objective, timeout=60)GPUを搭載した端末でプログラムを実行するので、174行と175行でGPUを使用する設定を行っています。
'tree_method': 'gpu_hist', # gpuを使う設定
'predictor': 'gpu_predictor', # gpuを使う設定プログラムの実行結果
プログラムを実行すると下記を出力します。
- R2、MAE、RMSEの計算結果
- 実タイムと予測タイムの散布図
- 予測タイムに対する重要度分析
- ハイパーパラメータの最適値
<1. R2、MAE、RMSEの計算結果>
r2: 0.9300187227992001
mae: 4.0897017579161075
rmse: 4.92142905771823<2. 実タイムと予測タイムの散布図>

<3. 予測タイムに対しての重要度分析>

<4. ハイパーパラメータの最適値>
ハイパーパラメータの最適値: {'max_depth': 7, 'min_child_weight': 9, 'eta': 0.5424389974750153, 'subsample': 0.22534018506755105, 'colsample_bytree': 0.9560800917894695, 'alpha': 0.1770593315851091, 'lambda': 0.031137786548939422, 'gamma': 0.6502218704493107}予測結果の確認
今回と前回の評価結果を比較すると、全ての評価項目で向上していました。
| 評価項目 | 今回の評価結果 | 前回の評価結果 |
| R2 | 0.930 | 0.724 |
| MAE | 4.089 | 7.779 |
| RMSE | 4.921 | 9.051 |
今回と前回の評価結果を比較すると、前回の的中率より下がっていました。
| 今回の的中率 | 前回の的中率 |
| 4.61% | 8.22% |
実タイムと予測タイムの差は減りましたが、的中率は下がりました。
出力された[比較結果.csv]を流し読みしていると、1着と2着は割りと的中しているように見えました。
また、三連複の買い方は、あまり初心者向けの買い方でないことを知りました。
単勝、複勝での的中率を算出できるようにもしてみます。
次回、試したいこと
- 単勝、複勝での的中率を算出する
- 過学習、未学習なのかを可視化する
- 特徴量を自動生成するAutoFeatを試す
- AutoMLのFlaml、auto-sklearnを試す
まずは、簡単なところから順に試していきます。


コメント