
はじめに
前回、2022年5月22日~6月22日の間に開催されたレースの出走馬のタイム予測を行いました。タイム予測の結果で、3連複馬券を購入した際の的中率を算出するプログラムを作成してみました。
概要
各レースの出走馬の予測したタイムから予測順位を出します。
予測順位と実順位を比較し、3連複となった場合は「当たり」とし、それ以外は「外れ」としています。実順位と一致する必要はなく、1着、2着、3着となる馬の組み合わせ、で「当たり」を判定しています。
的中率は以下のパターンで計算してみました。
予測モデルを2013年から1年ごとに短くして作成し、2022年6月のタイム予測を行いました。各予測モデルの的中率を計算してみました。
| 予測に使ったレース結果 | 2022年6月の的中率 |
| 2013年1月~2022年5月 | |
| 2014年1月~2022年5月 | |
| 2015年1月~2022年5月 | |
| 2016年1月~2022年5月 | |
| 2017年1月~2022年5月 | |
| 2018年1月~2022年5月 | |
| 2019年1月~2022年5月 | |
| 2020年1月~2022年5月 | |
| 2021年1月~2022年5月 | |
| 2021年1月~2022年5月 |
プログラム概要
プログラムの概要は下記となります。
| 該当行 | 概要 |
| 1~2行 | ライブラリ読み込み |
| 5~14行 | 関数:レース結果に実順位を付ける |
| 17~28行 | 関数:予想の当たり1/外れ0を返す |
| 31~37行 | 関数:レース結果に予測順位を付ける |
| 40~50行 | 関数:レース名と開催場所をラベルエンコーディング |
| 53~55行 | 関数:重複を排除したレース名を抽出する |
| 58~90行 | メイン:各関数を呼び出して勝率を計算する |
作成したプログラム
34行目で予測結果を読み込んでいます。
今回使用したファイルは、前回作成した「予測結果.csv」を使用しています。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 実順位を追加する
def assign_rank(df):
df_tmp = df.copy()
df_tmp['実順位'] = range(1, len(df.index) + 1)
# 予測順位を追加する
df_predictsort = df_tmp.sort_values('予測タイム')
df_predictsort['予測順位'] = range(1, len(df_predictsort.index) + 1)
return df_predictsort
# 予想の当たり1/外れ0を返す
def hits_misses(df):
df_tmp = df.copy()
df_tmp_sort = df_tmp.sort_values('実順位')
df_tmp_predict_top3 = df_tmp_sort.iloc[:3, df_tmp_sort.columns.get_loc('予測順位')]
# 実順位の合計が6(1位+2位+3位)だった場合は当たり、それ以外は外れ
# 当たりは1、外れは0を返す
if df_tmp_predict_top3.sum() == 6:
return 1
else:
return 0
# 予測結果を追加したレース結果を読み込む
def read_race_result():
# レース結果を読み込む
df = pd.read_csv('./予測結果.csv', encoding='cp932')
df.drop('Unnamed: 0', axis=1, inplace=True)
return df
# レース名と開催場所をラベルエンコーディング
def labelencode_race_venue(df):
le = LabelEncoder()
racename_encoded = le.fit_transform(df['レース名'].values)
df['レース名_エンコード'] = racename_encoded
le = LabelEncoder()
venue_encoded = le.fit_transform(df['開催場所'].values)
df['開催場所_エンコード'] = venue_encoded
return df
# 重複を排除したレース名の抽出
def list_unique_race(df):
return df['レース名_エンコード'].unique()
def main():
# レース結果を読み込む
df_predict_result = read_race_result()
# レース名と開催場所のラベルエンコードを行う
df_predict_result = labelencode_race_venue(df_predict_result)
# レース名_エンコードのユニークを抽出する
race_encoded_list = list_unique_race(df_predict_result)
num_hits = 0 # 当たりの数
num_races = 0 # レースの数
# 同一レース名があるので、レース名と開催場所でレース結果を絞る
for i in race_encoded_list:
df_race = df_predict_result[df_predict_result['レース名_エンコード'] == i]
venue_encoded_list = df_race['開催場所_エンコード'].unique()
for j in venue_encoded_list:
df_race_venue = df_race[df_race['開催場所_エンコード'] == j]
# 実順位と予測順位を追加する
df_race_venue_assign_rank = assign_rank(df_race_venue)
# 当たり外れを判定する
count = hits_misses(df_race_venue_assign_rank)
num_hits += count
num_races += 1
print('レースの数:', num_races)
print('当たりの数:', num_hits)
print('的中率:', '{:.2%}'.format(num_hits/num_races))
if __name__ == "__main__":
main()プログラムの補足
「関数:レース名と開催場所をラベルエンコーディング」について
レース名:「3歳C2六組」は、開催場所:「6回水沢6日目」と開催場所:「5回水沢6日目」に実施されています。各レースの実順位と予測順位の付与と比較を行う際に、レース名だけで抽出してそれらを実行すると、「6回水沢6日目」と「5回水沢6日目」の2つの開催場所も含めて実行してしまいます。
以下の表は、レース名:「3歳C2六組」でレースを抽出した結果です。
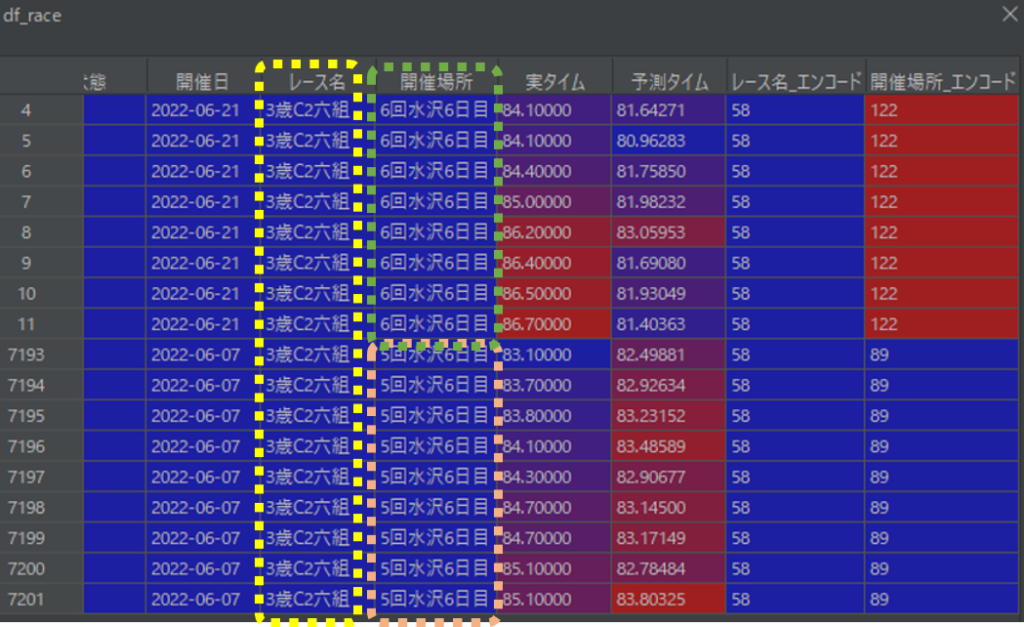
レースを抽出する際は、開催場所を加えて抽出します。
大まかな流れは下記となります。
- レース名でレース結果を抽出する
- 抽出した結果から開催場所を抽出する
- レース名+開催場所で的中率計算を行う
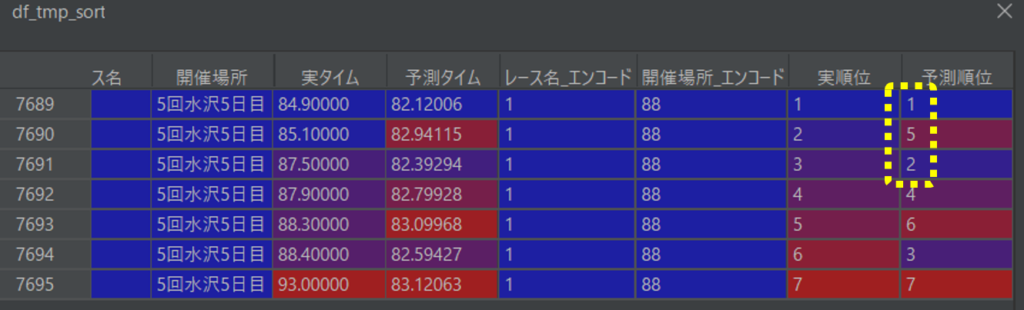
「関数:予想の当たり1/外れ0を返す」について
勝率の「勝ち(当たり)」の定義は「3連複を当てる」としています。
「3連複」は1着、2着、3着となる馬の組み合わせを当てる、です。
実順位で昇順でソートした際の、予測順位の上位3つの合計を計算します。
上位3つの合計が6(=1+2+3)であった場合、「3連複が当たった」と判定しています。
下記の場合は、1+5+2=8なので「外れ」と判定します。
プログラムの実行結果
プログラムを実行すると、予測したレースの数、当たりの数、的中率を表示します。
レースの数: 1301
当たりの数: 110
的中率: 8.46%予測結果の勝率
勝率が高かったのは、2019年1月~2022年5月のレース結果を予測に使った予測モデルで10.22%でした。
この的中率が高いのか低いのか、競馬の素人なので理解していません。
「低い」気はしています。。。
どちらかと言うと、仮にこの通りに馬券を買ったとしたときの費用回収率のほうが気になりました。
| 予測に使ったレース結果 | 2022年6月の的中率 |
| 2013年1月~2022年5月 | 8.46% |
| 2014年1月~2022年5月 | 8.61% |
| 2015年1月~2022年5月 | 7.92% |
| 2016年1月~2022年5月 | 9.07% |
| 2017年1月~2022年5月 | 8.15% |
| 2018年1月~2022年5月 | 10.22% |
| 2019年1月~2022年5月 | 8.61% |
| 2020年1月~2022年5月 | 8.30% |
| 2021年1月~2022年5月 | 8.22% |
| 2021年1月~2022年5月 | 6.46% |
次回、試したいこと
3連複で的中率を計算しましたが、他の買い方でも計算してみます。
ここ基準に予測モデルの向上を目指します。特徴量の調整やpycaretなどを使って色々と試してみます。


コメント