結論
RepeatVectorを利用するとシンプルに構築できました。
経緯
モデルを作成した際、予測範囲を増やす方法として下記の方法があります。
予測データを次の予測データの算出に使う方法となります。
- ①検証データ1で予測データAを算出する
- ②検証データ1の最初のデータを削除し、検証データ2を作成する
- ③予測したデータAを検証データ2の最後に追加する
- ④検証データ2で予測データBを算出する
- ⑤検証データ2の最初のデータを削除し、検証データ3を作成する
- ⑥予測したデータBを検証データ3の最後に追加する
- ⑦検証データ3で予測データCを算出する

上記フローのコードを作成すること自体は可能ですが、もっとシンプルな方法で実現できないか。
調べたところ、RepeatVectorを使用するとシンプルに実現できることが判りました。
方法
7つのデータから、3つのデータを予測するモデルを作成してみました。
訓練データと教師データは下記の通りです。

コード
import numpy as np
# tensorflowのライブラリを読み込む
import tensorflow as tf
# 乱数シードを固定する
tf.random.set_seed(1234)
# kerasのライブラリを読み込む
from keras.models import Sequential
from keras.layers import Dense, LSTM, RepeatVector, TimeDistributed
# RMSEを計算するためにsklearnのライブラリを読み込む
from sklearn.metrics import r2_score, mean_squared_error
# 訓練データを用意する
x_train = np.array([
[1, 4, 7, 10, 13, 16, 19],
[2, 5, 8, 11, 14, 17, 20],
[3, 6, 9, 12, 15, 18, 21],
[4, 7, 10, 13, 16, 19, 22],
[5, 8, 11, 14, 17, 20, 23],
[6, 9, 12, 15, 18, 21, 24],
[7, 10, 13, 16, 19, 22, 25],
[8, 11, 14, 17, 20, 23, 26]])
# 教師データを用意する
y_train = np.array([
[22, 25, 28],
[23, 26, 29],
[24, 27, 30],
[25, 28, 31],
[26, 29, 32],
[27, 30, 33],
[28, 31, 34],
[29, 32, 35]])
# 訓練データと教師データをLSTMで読み込める形式に変換する
x_train = x_train.reshape((x_train.shape[0], x_train.shape[1], 1))
y_train = y_train.reshape((y_train.shape[0], y_train.shape[1], 1))
# モデルを定義する
model = Sequential()
# 隠れ層の数は、10とする
# 活性化関数はreluに設定する
# input_shapeは、1回に入力するデータ=1行分のデータ、となる
model.add(LSTM(10, activation='relu', input_shape=(x_train.shape[1], x_train.shape[2])))
# 予測数の指定は、RepeatVectorで設定する。1回あたりの教師データの数が予測数となる。
model.add(RepeatVector(y_train.shape[1]))
# RepeatVectorを設定しているので、return_sequences=TrueとTimeDistributedを設定する
model.add(LSTM(10, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(1)))
# モデルの情報を表示する
model.summary()
# モデルを作成する
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルを訓練する
model.fit(x_train, y_train, epochs=1000, verbose=1)
# 検証データを用意する
x_test = np.array([12, 15, 18, 21, 24, 27, 30])
x_test = x_test.reshape((1, x_test.shape[0], 1))
# 正解データを用意する
y_test = np.array([33, 36, 39])
# 検証データを用いて予測する
y_predict = model.predict(x_test)
# 予測結果を1次元化する
y_predict = np.ravel(y_predict)
# 予測データを表示する
print(f'予測結果: {y_predict}')
# モデルの精度を評価する
# R2、RMSEを計算する。R2は1.0に、RMSEは0.0に近いほど、モデルの精度は高い
r2_score = r2_score(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
print(f'r2_score: {r2_score:.4f}')
print(f'rmse: {rmse:.4f}')下記のデータで作成したモデルが想定通りに3つの予測データを算出するかを確認しました。

実行結果
予測結果: [32.80152 35.688915 38.342003]
r2_score: 0.9684
rmse: 0.4356RepeatVectorとTimeDistributedについて
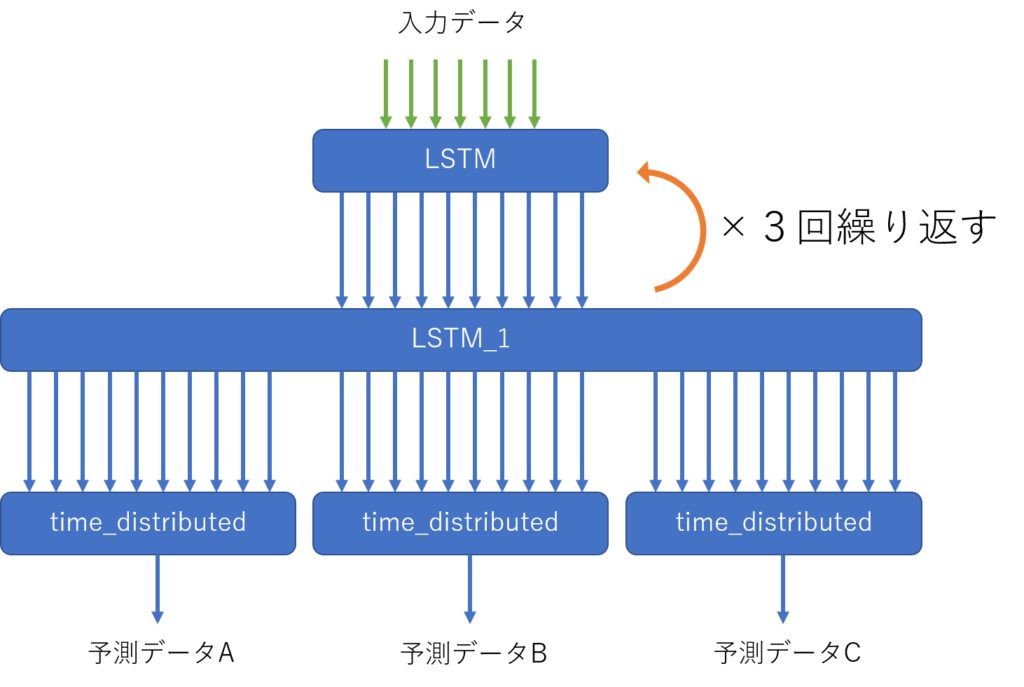
作成したコードのポイントとなるのは、RepeatVectorとTimeDistributedの設定となります。
該当するコードは下記となります。
# 予測数の指定は、RepeatVectorで設定する。1回あたりの教師データの数が予測数となる。
model.add(RepeatVector(y_train.shape[1]))
# RepeatVectorを設定しているので、return_sequences=TrueとTimeDistributedを設定する
model.add(LSTM(10, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(1)))RepeatVectorで予測数(1回あたりの教師データの数)を指定します。
TimeDistributedで出力する数を1にしています。
概念図(間違えているかもしれませんが)


コメント
始めてお便りを差し上げます。
貴方の下記3文献を参考に株関係の予測をtryし、他の方法より感覚的に良い結果を算出できたように感じています。
PythonでKerasのLSTMを用いて、株価の予測を試してみた #https://relaxing-living-life.com/128/
PythonでKerasのLSTMを用いて、複数の情報を基に株価の予測を試してみた #https://relaxing-living-life.com/147/
LSTMでモデルを作成した際、シンプルな方法で予測する範囲を増やしたい #https://relaxing-living-life.com/174/
ただ、KerasでのLSMTへのデータの渡し方が疑問点として、引っ掛かりまして、教えていただければとメールさせていただいた次第です。
あなたの渡し方は、
文献、#Kerasで多変量LSTM #https://qiita.com/tizuo/items/b9af70e8cdc7fb69397f
と同じく
1.input_shapeには、変数個数とルックバック数が入ります
2.データをkerasのLSTMで受け付けられている形式に変換します。[行数]>[変数数]>[カラム数(ルックバック数)]
ですが、
2.に関しては以下の文献
TensorFlow 2.x での多変量LSTMとデータの前処理 #https://qiita.com/ell/items/34f069651b551709d127
にて
訓練データのNumpy配列について、、LSTMを多変量データで学習させるとき、データは [サンプル数, ルックバック数, 変数数] という形式でないといけません(超重要!)。
ここで、ルックバック数とは「過去何回分のデータを1つのデータとするか」を意味します。
との記述があり、混乱している次第です。
よろしくお願いします。
2022.06.12 irino